So you wired up CodeDeploy, pushed a deploy, CodeDeploy reported success - and your users were getting 502s. Welcome to the club. If you're here because you're trying to get aws cdk codedeploy ec2 auto scaling working properly in production - not just the tutorial skeleton that falls apart on the first real load event - this one's for you.
Who Is This For
You're a backend or DevOps engineer who's already comfortable with CDK and AWS. You've probably shipped a few stacks. You know what an ALB is. You're not here for "what is Auto Scaling." You're here because you're trying to wire CodePipeline → CodeBuild → CodeDeploy → ASG in a way that actually holds up under load, handles rollbacks, and doesn't wake you up at 2 AM.
This is also for teams who've been burnt by container migrations - maybe ECS isn't the right fit right now, maybe the app has a bunch of stateful assumptions, maybe the org just isn't ready - and you need EC2-based deployments to be production-grade, not "good enough for now."
Problem and Why It Matters
OK so here's what nobody tells you about CodeDeploy + Auto Scaling + ALB: the compute layer is the easy part.
The hard part is the coordination layer. CodeDeploy has its own definition of "healthy." The ALB has its own definition. The ASG has its own definition. And all three of them need to agree - or you get a deploy that's technically successful while your users stare at 502s. Right?
I've seen this exact thing happen twice on client projects. Both times, the deploy pipeline was green. Both times, CloudWatch showed the EC2 instances as running. Both times, the ALB was quietly draining targets because the health check path was returning 404 during the ApplicationStart lifecycle phase - right when the new app version was still spinning up. CodeDeploy didn't know. The ASG didn't know. The ALB just silently removed the instances from rotation and called it a day.
This blew my mind the first time I saw it.
And then there's the rollback problem. Everyone assumes rollback works. It does - until it doesn't. If your S3 artifact bucket has an aggressive lifecycle policy that deleted the previous revision, CodeDeploy will tell you it's rolling back and then fail because there's nothing to roll back to. That's a fun 3 AM discovery. (I learned this the hard way on a Friday deploy.)
The operational glue - SSM parameters for runtime config, SNS for deploy notifications, EventBridge for pipeline state changes, CloudWatch alarms - that's what separates "we have CodeDeploy" from "we have a production deployment system."
When This Approach Fits
EC2 + CodeDeploy is still the right call in a few specific situations. Don't let anyone bully you into ECS if these apply:
- Your app has persistent local state, IPC between processes, or syscall requirements that make containers awkward
- You're doing fewer than ~10 deploys per day and the 5-15 minute CodeDeploy lifecycle overhead is acceptable
- The team owns the OS and runtime environment and wants to keep it that way
- You have compliance or licensing requirements tied to specific machine configurations
- You're migrating a legacy app and containerizing it is a quarter-long project, not a sprint
If you're doing 20+ deploys a day and speed matters, containers are genuinely better. But for the workloads where EC2 fits, this architecture gives you zero-downtime rolling deploys without the ECS/EKS operational surface area.
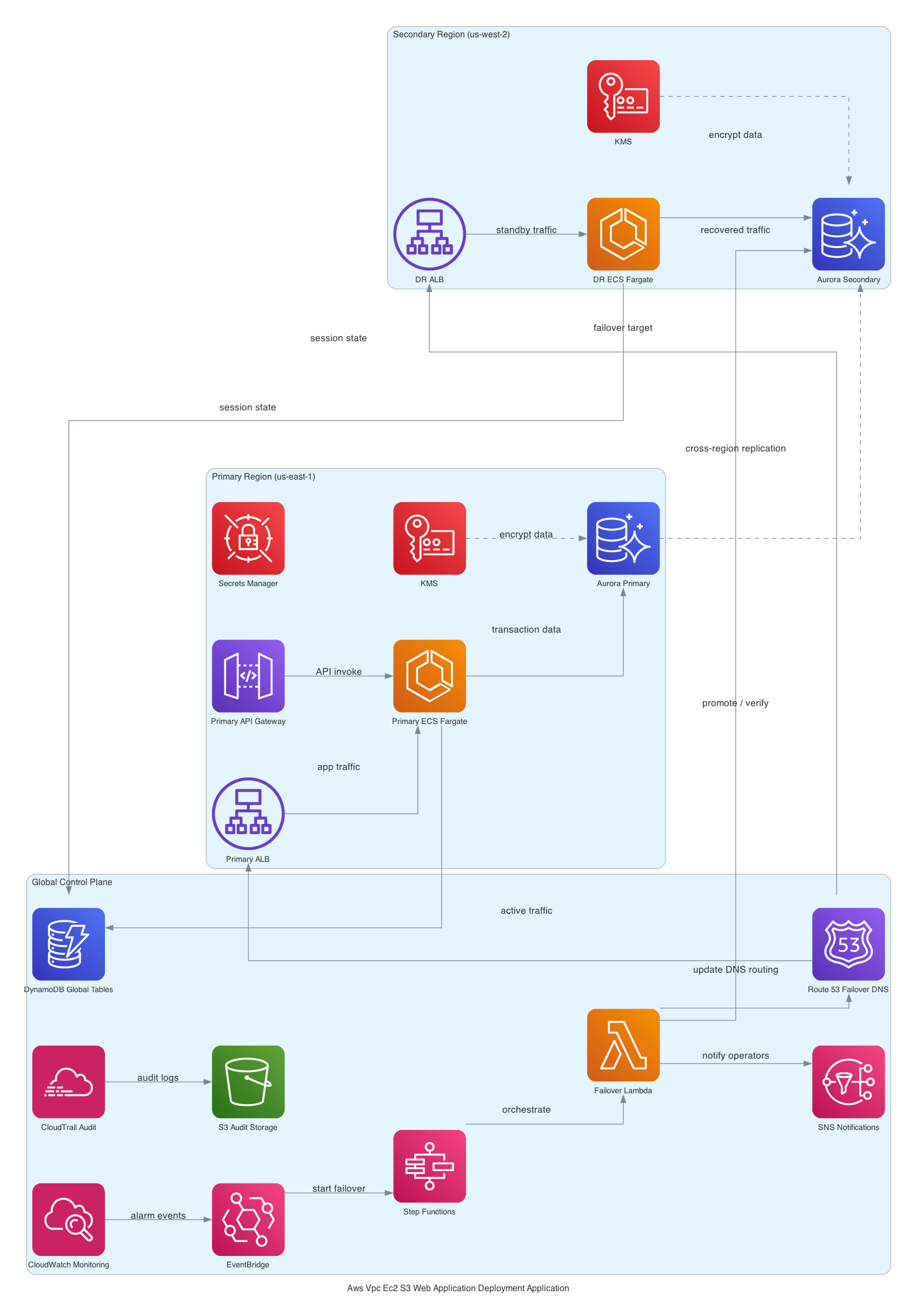
Architecture or Implementation Overview
So basically it's a layered model - standard, but the details matter.
Network tier: Custom VPC with public and private subnets across 2 AZs. ALB lives in the public tier (internet-facing). EC2 instances live in the private tier with no direct internet exposure. The subnet design here follows the pattern I covered in the VPC subnet design for EC2 workloads guide - if you're not sure how many AZs or what your CIDR blocks should look like, start there.
Compute tier: Auto Scaling Group in the private subnets. Instances pull from SSM Parameter Store for runtime config - no secrets baked into AMIs, no environment variables in user data. The CodeDeploy agent runs on each instance and polls for deployment instructions.
CI/CD spine: S3 as the artifact store. CodePipeline orchestrates source → build → deploy. CodeBuild handles the build stage. CodeDeploy runs rolling deployments onto the ASG using deployment groups tied to the ASG directly. [from-code]
Observability: CloudWatch log groups (with explicit retention - more on why that matters in the cost section) and alarms on the key signals. EventBridge routes pipeline state change events downstream. SNS handles notifications. [from-code]
And here's the kicker - the non-obvious piece: CodeDeploy needs to know about the ALB. You configure the deployment group with the ALB target group, which tells CodeDeploy to deregister instances from the ALB before installing the new version and re-register after - that's how you get zero-downtime rolling deploys. If you skip this wiring, CodeDeploy will happily deploy while the ALB is still routing traffic to instances being updated. You'll see errors. Not a lot of errors. Just enough to be mysterious.
Step-by-Step Implementation
Here's a sanitized CDK snippet showing the ALB-to-ASG wiring - this is actually the part most examples gloss over:
// ALB → Target Group → ASG wiring
const targetGroup = new elbv2.ApplicationTargetGroup(this, 'AppTargetGroup', {
vpc,
port: 8080,
protocol: elbv2.ApplicationProtocol.HTTP,
targetType: elbv2.TargetType.INSTANCE,
healthCheck: {
path: '/health', // Make sure this exists and returns 200 BEFORE app starts
healthyThresholdCount: 2,
unhealthyThresholdCount: 3,
interval: Duration.seconds(30),
timeout: Duration.seconds(10),
},
deregistrationDelay: Duration.seconds(60), // Give in-flight requests time to drain
});
// ASG registers itself with the target group
asg.attachToApplicationTargetGroup(targetGroup);
// CodeDeploy deployment group knows about the ALB
const deploymentGroup = new codedeploy.ServerDeploymentGroup(this, 'DeploymentGroup', {
application: codeDeployApp,
autoScalingGroups: [asg],
loadBalancer: codedeploy.LoadBalancer.application(targetGroup),
deploymentConfig: codedeploy.ServerDeploymentConfig.ONE_AT_A_TIME,
installAgent: true,
});
A few things worth calling out here:
The health check path. /health needs to return HTTP 200 before the application is fully started. You know how some apps take 30 seconds to warm up their caches and connection pools? If your health check fires every 10 seconds with a timeout of 5 during that window - you're going to drain instances during every single deploy. Set healthyThresholdCount: 2 and give yourself some breathing room on the interval.
deregistrationDelay: This is 300 seconds by default. For most EC2 apps, that's five whole minutes of waiting during every rolling deploy. Drop it to 30-60 seconds unless you have genuinely long-lived connections.
ONE_AT_A_TIME vs HALF_AT_A_TIME: For smaller fleets (under ~10 instances), ONE_AT_A_TIME is safer during rollouts. For larger fleets, HALF_AT_A_TIME is faster but means half your fleet is unavailable during the install phase. Pick based on your fleet size and traffic patterns.
The complete IAM role construction, the appspec configuration, and the lifecycle hook setup for ASG suspension during deploys are in the paid tier - that's where the real "here's why this breaks" content lives.
Trade-offs
Deploy speed vs. operational simplicity. CodeDeploy lifecycle hooks (BeforeInstall, AfterInstall, ApplicationStart, ValidateService) add 5-15 minutes per rolling deploy. [inferred] If you're doing 10+ deploys a day, that overhead compounds fast. Container swaps on ECS are measured in seconds. EC2 CodeDeploy is measured in minutes. That's not a bug - it's just the cost of the model.
S3 artifacts vs. container images. Zip-based artifacts are simple and cheap, but you lose layer caching and immutable image semantics. [editorial] Every deploy re-transfers the full artifact. For small apps, irrelevant. For apps with 500MB of dependencies, it adds up.
SSM Parameter Store. Standard tier is free up to 10,000 parameters. But if you ever cross into advanced tier territory, it's $0.05 per parameter per month. Oh, and another thing - the sneaky part: teams actually hit TooManyUpdates throttling errors during high-frequency deploys - the CodeDeploy agent and the app both making SSM calls simultaneously - and it shows up as mysterious deploy failures that look like network issues. Classic AWS. [inferred]
Failure Modes
The one I see most: CodeDeploy reports success, ALB shows 502s. This happens when the ALB health check path doesn't exist or isn't returning 200 during the ApplicationStart phase. CodeDeploy considers the instance healthy once the ApplicationStart hook exits successfully. The ALB has its own opinion based on the health check. They're not synchronized - right? You need to build in a ValidateService hook that waits until the ALB health check is actually passing before CodeDeploy marks the deploy done. [editorial]
Rollback with nothing to roll back to. If your S3 artifact bucket lifecycle policy deletes old versions aggressively, a failed deploy has no previous revision to restore. Set a minimum retention of 30 days on your artifact bucket. Don't let lifecycle policies clean up what CodeDeploy needs to save you at 3 AM.
Not ideal.
Scale-in during deploy. ASG decides to terminate an instance mid-deploy because a scale-in event fires. CodeDeploy reports partial success on a shrinking fleet. The fix: suspend the Terminate scaling process during deployment using a lifecycle hook on the ASG. Most CDK examples skip this entirely. (Don't ask how long this took me to diagnose.)
Silent pipeline failures. Without a CloudWatch alarm on FAILED state transitions from your EventBridge rules, a stuck pipeline can go unnoticed for hours. Create the alarm. CloudWatch alarms for EC2 Auto Scaling fleets covers this pattern in detail.
Security and Operational Considerations
IAM is where this architecture is most likely to fail a security audit. CDK's default managed policies for CodeBuild and CodeDeploy are broad. AWSCodeBuildAdminAccess on a CodeBuild role is not least-privilege - it's "I'll tighten this later" and "later" never comes. IAM least privilege for CodeBuild and CodeDeploy walks through the specific permission sets you actually need.
EC2 instance profiles need SSM access (for Parameter Store reads), CloudWatch Logs access (for the agent), and S3 access (to pull deployment artifacts). That's it. Nothing else.
SNS email subscriptions require manual confirmation. Teams automate everything, forget to click the confirmation link, and discover their deploy notification channel is completely silent on the first real incident. Automate the subscription to an SQS queue or Lambda instead if you want reliable delivery. Seriously.
Cost Reality
Let's put real numbers on this for a modest fleet (5 EC2 instances, t3.medium, us-east-1):
- EC2 (5x t3.medium On-Demand): ~$170/month
- ALB: ~$20/month base + data processing charges
- NAT Gateway (private subnet egress): ~$54/month just for the gateway, plus $0.045/GB
- CodePipeline: $1/month per active pipeline
- CodeBuild: First 100 build minutes/month free, then $0.005/minute
- S3 (artifact storage): <$5/month for most teams
- CloudWatch Logs (with default never-expire retention): $50-200/month for a busy fleet [inferred]
That CloudWatch Logs number is actually the one that surprises people. If you're running verbose app logs on 5 EC2 instances with no retention policy, you're paying $0.50/GB to ingest and $0.03/GB/month to store. Set explicit retention on every log group - 30 days is usually right, 90 days max unless you have compliance requirements. Don't accept the CloudWatch default of "forever."
For a more detailed breakdown of where CI/CD pipeline costs actually go, the CI/CD pipeline cost breakdown on AWS has the full analysis.
What I'd Do Differently
Honestly? Three things.
1. VPC endpoints from day one. I've set up this pattern twice without VPC endpoints and paid for NAT Gateway egress for SSM, S3, and CloudWatch Logs calls - all traffic that never needed to touch the internet. VPC endpoints for these services are either free (gateway endpoints for S3 and DynamoDB) or ~$7/month per endpoint. Way cheaper than NAT Gateway egress at scale.
2. Skip the email SNS subscription. Use an SQS queue → Lambda → Slack/PagerDuty chain instead. Email subscriptions require manual confirmation, have unreliable delivery, and no one checks their AWS notification email inbox. Build the automation from day one.
3. Validate the ALB health check before the first real deploy. Sounds obvious. Almost nobody does it. Hit the /health endpoint manually from an instance in the private subnet. Make sure it returns 200 in under your timeout. Then deploy. Don't discover the health check is broken during the deploy.
Next Step
If you got this far, here's what to look at next depending on where you are:
free: The CDK infrastructure patterns for production AWS post covers the broader CDK patterns this stack builds on - useful if you're still feeling out how to structure multi-stack CDK apps.
paid: The full CDK TypeScript source for this stack, including IAM role construction with least-privilege scoping, the complete appspec.yml with lifecycle hook configuration, the EventBridge → SNS notification chain, the ASG lifecycle hook that suspends termination during deploys, and the three alternative architectures we considered (ECS Fargate, CodeDeploy with blue/green, and Lambda-based deploys) with honest pros and cons for each.
The deploy pipeline that doesn't wake you up at 2 AM is mostly a config problem, not a compute problem. Get the lifecycle hooks right, get the health checks aligned, and set your log retention. Everything else is just wiring.