So you've built a Kinesis Firehose to OpenSearch CDK pipeline, it deploys clean, the green checks feel good - and then at 3am your on-call phone goes off because users are reporting a 45-minute gap in your analytics dashboard and nobody can explain where 200,000 events went. That's the story this post is about. Not the happy path. The quiet failure surfaces that serverless abstractions hide from you until they really, really don't.
Who Is This For
If you're a senior engineer or architect who already knows what Kinesis, Firehose, and OpenSearch are and you're trying to wire them together in CDK TypeScript without flying blind - this is for you. I'm not going to explain what a shard is. I'm assuming you've been burned by a misconfigured buffer interval or a stalled Lambda consumer at least once and you want to build the version that doesn't surprise you.
If you're just getting started with CDK or streaming data in general, bookmark this and come back. This one goes deep fast.
Problem and Why It Matters
Here's the actual problem: "serverless" doesn't mean "simple to operate." It means you've traded EC2 uptime alerts for eight distinct async failure surfaces, none of which page you by default.
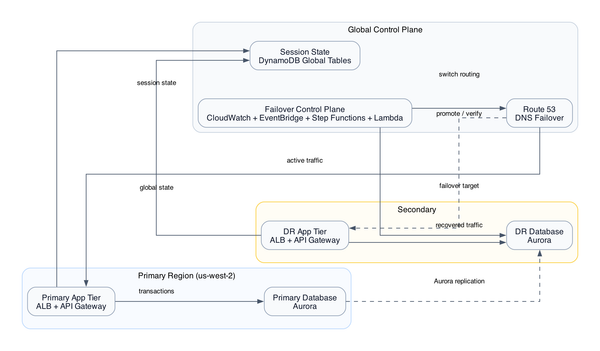
Think about what you're actually stitching together. API Gateway receives events. Lambda validates and forwards to Kinesis Data Streams. Firehose buffers and lands raw payloads to S3. Kinesis Analytics runs SQL transformations in flight. OpenSearch gets the hot path for near-real-time search. DynamoDB handles low-latency key lookups. Glue crawlers catalogue the S3 raw zone. Athena runs ad-hoc queries without a warehouse. SNS and SQS handle dead-letter routing. KMS encrypts everything.
That's 16 services. Every hand-off between them is an async boundary. Every async boundary is a place where data can disappear silently.
The specific failure that kills teams is this: Firehose has a default buffer of 5 minutes or 128 MB, whichever comes first. A misconfigured buffer interval means Firehose holds your data. If your OpenSearch domain is undersized and starts rejecting bulk index requests, Firehose retries quietly, backs up to an S3 error prefix, and sends you... nothing. No alarm. No page. Just a gap in your dashboard that someone notices when they ask "why does our event count look weird between 2:15 and 3:00 AM?"
And that's just one failure surface. There are seven more.
When This Approach Fits
This stack makes sense when you need ordering guarantees and replay capability, not just throughput.
If your event volume is low and you don't care about message ordering - honestly, SQS plus Lambda is 80-90% cheaper and operationally much simpler. I mean that. Kinesis with provisioned shards costs roughly $10.95/shard/month just to exist, before a single event flows through.
But when you need Kinesis, you really need it. Ordered delivery within a shard. Seven-day replay so you can reprocess events when your downstream schema breaks. The fan-out pattern where multiple consumers read the same stream independently. If those things matter to you - and in financial events, clickstreams, or audit logs they almost always do - this architecture is the right call.
The dual-sink pattern - feeding both OpenSearch and DynamoDB from the same enriched stream - is the non-obvious design choice here. You're paying for write amplification, but you're buying query flexibility without a secondary ETL job. OpenSearch for full-text search and near-real-time dashboards, DynamoDB for low-latency single-record lookups. Different query shapes, same data, one write path. Most teams would reach for this if they thought about it, but they don't because CDK makes it easy to just pick one sink and stop there.
Architecture or Implementation Overview
Let me walk you through the data flow before we get into code.
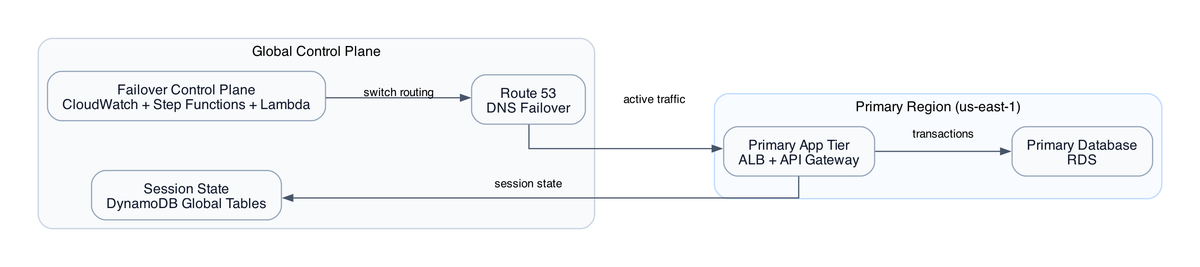
API Gateway → Lambda (validate + forward) → Kinesis Data Streams
↓
Kinesis Analytics (SQL enrichment)
↓ ↓
OpenSearch DynamoDB
Kinesis Data Streams → Firehose → S3 (raw zone)
↓
Glue Crawler → Athena
The hot path is Kinesis Data Streams through Kinesis Analytics to OpenSearch. Sub-minute latency, search and dashboards. The cold path is Firehose to S3 to Glue to Athena - durable storage for historical queries and data recovery.
Both paths share the same source stream but serve completely different latency requirements. The hot path accepts seconds of lag. The cold path accepts up to a 5-minute buffer window. If you need sub-minute alerting, you need the hot path. If you need ad-hoc queries over months of history, you need the cold path. Most teams actually need both.
Step-by-Step Implementation
Here's the one CDK snippet I'm sharing free because it contains the single most important operational decision in this entire stack - bisect-on-error on the Kinesis event source mapping.
// kinesis-stream-consumer.ts
const stream = new kinesis.Stream(this, 'EventStream', {
shardCount: 2,
retentionPeriod: Duration.days(7),
encryption: kinesis.StreamEncryption.KMS,
encryptionKey: sharedCmk,
});
const consumerFn = new lambda.Function(this, 'StreamConsumer', {
runtime: lambda.Runtime.NODEJS_20_X,
handler: 'index.handler',
code: lambda.Code.fromAsset('lambda/consumer'),
environment: {
OPENSEARCH_ENDPOINT: osDomain.domainEndpoint,
DYNAMODB_TABLE: table.tableName,
},
});
consumerFn.addEventSource(
new lambdaEventSources.KinesisEventSource(stream, {
startingPosition: lambda.StartingPosition.TRIM_HORIZON,
batchSize: 100,
bisectBatchOnError: true, // THIS IS THE ONE
retryAttempts: 3,
maxRecordAge: Duration.hours(24),
reportBatchItemFailures: true,
})
);
bisectBatchOnError: true is the thing. Without it, a single poison-pill record - bad JSON, oversized payload, whatever - stalls your entire shard. Lambda retries the whole batch. The bad record is still in the batch. Lambda retries again. Your shard iterator age starts climbing. You get paged at 3am. With bisectBatchOnError: true, Lambda bisects the failing batch repeatedly until it isolates the bad record, processes the good ones, and sends only the bad one to your DLQ. This is the difference between a minor irritant and a full incident. One line. No excuses for not having it.
The full tap-stack.ts walkthrough - Firehose-to-OpenSearch IAM role construction, Glue crawler trigger wiring, the Kinesis Analytics SQL application construct - those are in the paid tier. The IAM wiring alone for Firehose is subtle enough that I've seen it wrong in production at multiple companies (don't ask how long it took me to spot the first one). Worth reading CDK IAM least privilege patterns before you attempt it.
Trade-offs
Kinesis vs SQS: Kinesis preserves ordering within a shard and gives you 7-day replay. SQS standard gives you neither. At low event volumes, SQS is dramatically cheaper. The decision really comes down to one question: do you need replay? If yes, Kinesis. If no, seriously reconsider.
OpenSearch managed service: A single-node dev domain runs $50-150/month minimum. At small event volumes, DynamoDB plus Athena covers most query patterns without index management overhead. OpenSearch earns its cost when you need full-text search, complex aggregations on recent data, or Kibana-style dashboards. If you're doing point lookups and simple filters, you're paying for features you don't need.
Firehose buffering: The default 5 min / 128 MB buffer is good for cost (fewer S3 PUT operations) but your cold path data is always 5 minutes stale. Fine for analytics. Completely disqualifying for alerting, which is exactly why OpenSearch gets the hot path via Kinesis Analytics. Don't try to use Firehose-to-S3 for sub-minute alerting. It won't work, and you'll spend an hour blaming your code before you blame the architecture.
KMS everywhere: Yes, encrypt everything. Yes, it adds per-API-call costs. At millions of events per day you're looking at an extra $20-60/month. Use one CMK across services with envelope encryption. Don't create a separate CMK per service - that's operationally painful and more expensive for no real benefit.
Failure Modes
This is the section that matters most. I'm going to be specific.
Iterator age breach: If your Lambda consumer falls behind - slow processing, errors, whatever - the Kinesis iterator age starts climbing toward your 7-day retention window. If it breaches retention, records expire. Gone forever. CloudWatch alarm on GetRecords.IteratorAgeMilliseconds is mandatory. Set the threshold at 1 day, not "above zero." One day gives you time to actually respond before data loss.
Poison pill stalls: Covered above, but worth repeating. Without bisectBatchOnError, one malformed event from a misbehaving upstream service will stall your shard for hours. The fix is one line of CDK. See the observability setup for catching these silently.
Firehose silent delivery failures: Firehose retries failed OpenSearch bulk index requests up to a configured limit. When retries exhaust, it writes to an S3 error prefix and sends you nothing. No alert. You have to add a CloudWatch alarm on DeliveryToElasticsearch.Success dropping below your expected delivery rate. If you skip this, you'll find out about the failure when someone runs a dashboard report. Classic AWS.
Glue schema drift: Lambda output schema changes, you forget to retrigger the Glue crawler, Athena queries return stale schema, results silently omit the new fields. No error anywhere. The fix is to trigger the Glue crawler from the same CDK pipeline that deploys schema changes. Wiring this correctly isn't trivial, but it's worth doing on day one.
Athena scan runaway: Without per-query data scan limits in your CDK workgroup configuration, a developer running an exploratory Athena query against an unpartitioned S3 prefix can scan terabytes. At $5 per TB that adds up fast. Set a query scan limit. I'd start at 10 GB per query for most workloads.
VPC Lambda ENI exhaustion: If your Lambda consumer is VPC-attached for private OpenSearch endpoint access, you're subject to ENI capacity limits. A traffic spike that exhausts available ENIs causes new Lambda invocations to fail, which cascades into shard processing delays. Lambda cold starts in VPC are already significantly longer (500ms-2s vs ~100ms). ENI exhaustion makes this much worse. I learned this the hard way.
Security and Operational Considerations
Least privilege on Firehose is where I see the most mistakes. The Firehose delivery role needs permission to read from Kinesis, write to S3, call OpenSearch bulk index, put error records to S3, and use your KMS CMK. That's five separate IAM policy statements. Most people copy-paste a wildcard from Stack Overflow and move on. Don't. The blast radius of an over-permissioned Firehose role is real.
KMS key policy for cross-service encryption needs explicit grants for each service principal. The CDK Key construct makes this easier than raw CloudFormation, but it's still easy to miss the Firehose service principal. Check it. Test it before production.
For the Kinesis Analytics application - if you add a new output destination after the initial deploy (say, wiring DynamoDB after OpenSearch is already running), the IAM role update needs to happen before you restart the Analytics application or you'll get permission denied errors that look like stream errors. It's confusing the first time you hit it.
Cost Reality
Real numbers at three scale points.
At 10 million events per month: Kinesis ($11 for 1 shard), Firehose (~$0.03 for data ingestion), Lambda ($0.20 for invocations), OpenSearch ($80 minimum for a dev domain), DynamoDB ($1-3 for writes and storage), S3 ($0.02), Glue ($1 for crawler runs), Athena ($0.50 for queries). Roughly $95-100/month total. OpenSearch is 80% of that bill.
At 100 million events per month: You'll need 2-3 Kinesis shards, Lambda costs climb to $2-5, DynamoDB write costs become meaningful at $10-30, OpenSearch stays similar if you sized it right initially. Total: $150-200/month.
At 1 billion events per month: Kinesis sharding gets expensive fast - 10+ shards at $110+/month. KMS API call costs become noticeable. Lambda concurrency needs careful tuning. You're in the $500-800/month range without OpenSearch cluster scaling, and OpenSearch at that ingestion rate needs a multi-node setup that runs $300-500/month by itself.
The headline: OpenSearch dominates cost at low scale. Kinesis shard costs dominate at high scale. The full breakdown per tier is in the paid section.
What I'd Do Differently
Honestly? I'd start without OpenSearch.
I know that sounds backwards. But at the start of most projects, you don't actually know your query patterns well enough to design OpenSearch indices correctly. You end up with a single index, no rollover policy, JVM heap pressure at 3am, and an incident. Start with DynamoDB for hot queries and Athena for historical queries. Add OpenSearch when you have a specific query pattern that neither can serve - full-text search, complex multi-field aggregations, that kind of thing.
Wire the Glue crawler trigger from day one, even if you're not running Athena queries yet. The schema drift failure mode is easy to miss and annoying to debug after the fact. Just wire it, test it, move on.
And set Athena query scan limits before anyone else touches the AWS console. Seriously. Do that first.
Next Step
The eight failure modes in this post are the ones I've seen in production. Firehose silent delivery failure and Glue schema drift are the two most likely to catch you, because neither one produces an obvious error - they just produce quietly wrong results.
If you want to actually build this stack without discovering these failure modes at 3am, the paid tier has the complete tap-stack.ts walkthrough with the Firehose-to-OpenSearch IAM role, Glue crawler trigger wiring, Kinesis Analytics SQL construct, and the exact CloudWatch alarm set that covers all eight failure surfaces.
free: Architecture diagram walkthrough, dual-sink design rationale, bisectBatchOnError Kinesis snippet, all eight failure modes described above.
paid: Full tap-stack.ts section by section, Firehose-to-OpenSearch IAM role construction, Glue crawler trigger wiring, Kinesis Analytics SQL application construct, cost breakdown at 10M/100M/1B events/month, exact CloudWatch alarm configuration for iterator age, Lambda errors, Firehose delivery failures, and OpenSearch JVM pressure.
For the observability side specifically - the CloudWatch alarms and what thresholds to set - the data pipeline observability post covers the alarm design philosophy in detail. Worth reading before you configure anything.
Build the alarms first. Then ship the pipeline.
Reference source code: github.com/InfraTales — production-ready AWS CDK (TypeScript) code for this architecture.