Who This Premium Deep Dive Is For
You're a staff or senior engineer at a fintech that's being told - not asked - to have EU data residency live before an audit deadline. You've used CDK before. You understand Lambda and DynamoDB at a conceptual level. What you need isn't another tutorial showing you how to create a table with a replica. You need someone who's looked at this architecture end-to-end and can tell you where the landmines are and in what order they'll explode.
This post is specifically for teams where the cutover window is measured in hours, not days, and where "we lost some transaction events during migration" is not an acceptable post-mortem entry. If you're doing a greenfield EU deployment with no existing transaction history to preserve, some of this still applies - but the stakes are different. The hard stuff here is all about the transition period.
Why This Is Premium
The public version of this post covers the architecture - Global Tables, weighted routing, Step Functions gates, S3 CRR. That's useful. But what makes this migration actually succeed is understanding three specific interactions that none of the individual service docs will warn you about.
The free tier gets you the what. This post gets you the why behind every design decision, the full six trade-off analysis with mitigations, the exact deployment sequence and bootstrap order across both regions, the cost breakdown (DynamoDB Global Tables replication write units are the budget killer nobody budgets for), and what breaks at scale beyond 10K TPS. You also get the three alternative architectures we considered and why we rejected each one.
Problem Framing
Here's the situation. You've got a fintech transaction system that's been living happily in us-east-1. GDPR compliance requires that EU user data be processed and stored in the EU. The audit deadline is not negotiable. And you need to get to eu-central-1 without losing a single transaction and without a maintenance window.
The classic traps are two. First, the big-bang migration - you flip DNS overnight, hold your breath, and discover at 2am that three payment processors are still talking to old endpoints. Second, the hand-rolled blue-green - you manually configure weighted routing, write a bunch of one-off scripts, and create a setup that works fine until your on-call engineer at 3am has to decide whether it's safe to shift another 20% of traffic.
This aws cdk multi-region migration fintech pattern exists to take both options off the table. The CDK stack codifies the entire phased migration as an orchestrated procedure. The cutover isn't a heroic act. It's a state machine with approval gates.
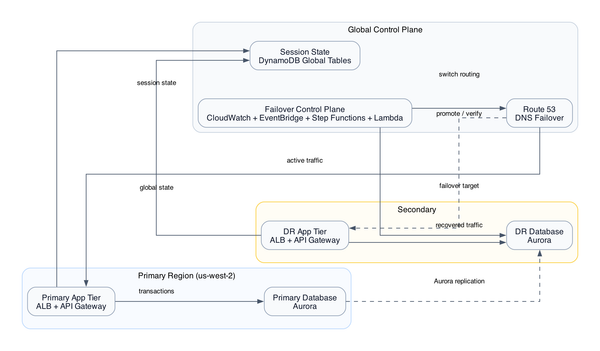
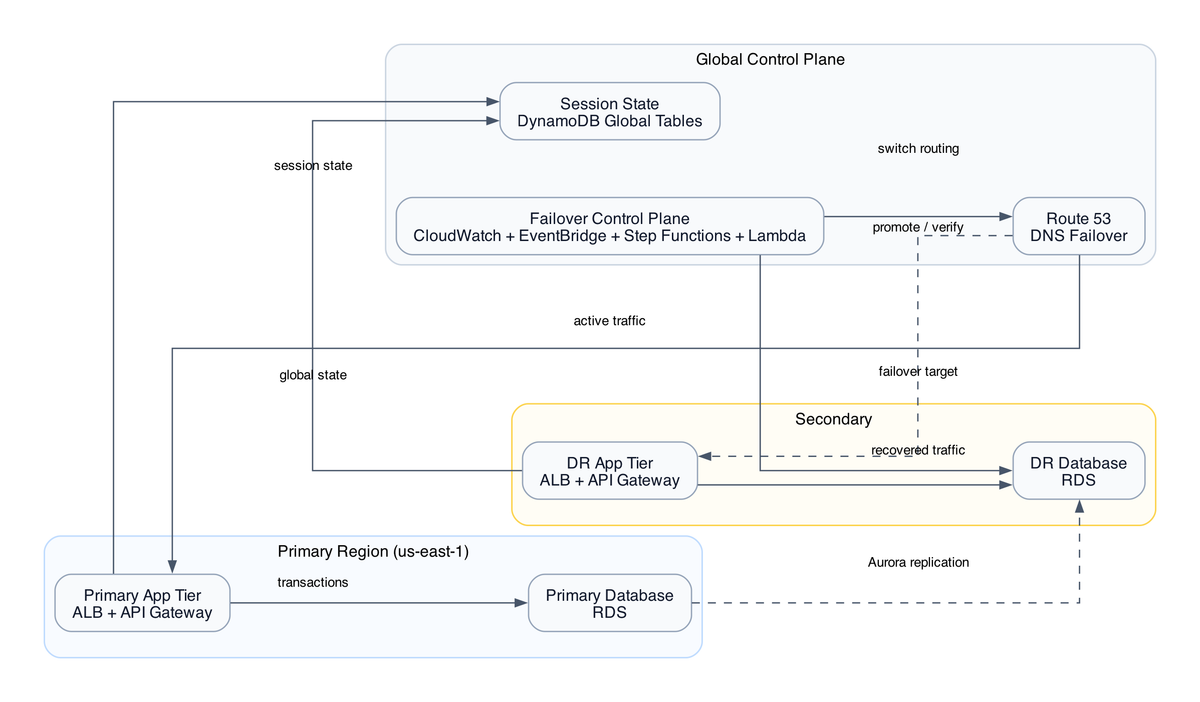
The architecture spans 10 services: DynamoDB Global Tables, Lambda in both regions, Route53 weighted routing, S3 with cross-region replication, CloudFront with origin failover, EventBridge cross-region event bus, Step Functions for orchestration, SSM Parameter Store for approval audit trails, CloudWatch for observability, and X-Ray for distributed tracing. Each one is individually straightforward. The interaction between them during the 72-hour post-cutover window is where the interesting problems live.
Deep Analysis or Annotated Implementation
Let me walk you through the three decisions that matter most in this design.
The Global Tables consistency model
Global Tables runs active-active replication with eventual consistency. Writes can happen in either region and propagate asynchronously. Replication lag is typically sub-second - usually 100-300ms - but "typically" is not a contract.
Here's the problem that bites payment systems specifically. Your idempotency check - "have I already processed this transaction ID?" - reads from DynamoDB before debiting an account. If that read hits the eu-central-1 replica and the write that created the idempotency record happened 200ms ago in us-east-1, you might get a miss. You process the transaction twice. The user gets double-charged. This is not a theoretical failure mode.
For read-heavy dashboards, eventual consistency is fine. For idempotency checks on payment debit operations, you need strongly consistent reads - which in Global Tables means reading from the primary region, which somewhat defeats the purpose. The mitigation (covered in the paid section with full code) is a conditional write pattern that uses DynamoDB's built-in conditional expressions to make the idempotency check atomic, regardless of which replica handles it.
Here's the free CDK snippet showing the Global Table construct, warts and all:
const transactionTable = new dynamodb.Table(this, 'TransactionTable', {
tableName: 'fintech-transactions',
partitionKey: { name: 'transactionId', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'timestamp', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
replicationRegions: ['eu-central-1'],
// WARNING: This will delete the table AND the eu-central-1 replica on cdk destroy.
// In a production account, you almost certainly want RETAIN here.
removalPolicy: cdk.RemovalPolicy.DESTROY,
pointInTimeRecovery: true,
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES,
});
That RemovalPolicy.DESTROY - I need to call this out explicitly. In the CDK code as provisioned, this is DESTROY. That means cdk destroy will attempt to delete the table and all replicas. In a production fintech account, this is a one-way door. No soft-delete, no recycle bin for DynamoDB. If you're deploying this pattern, change that to RemovalPolicy.RETAIN before you do anything else. I genuinely don't know why this was left as DESTROY in the source code - maybe it started as a test stack. But I've seen this exact configuration make it to production, and it's the kind of thing that only becomes a problem once. Once is enough.
The Step Functions approval gate pattern
This is the part I actually love about this design. Instead of trusting a cron job or a human to manually execute each migration phase, the state machine holds phase progression hostage behind a task token. The cutover literally cannot proceed without a human approving it in writing, and that approval is recorded in SSM Parameter Store. Step Functions task token approval pattern - see more architecture patterns on InfraTales
The flow: state machine reaches a phase boundary, publishes a task token to SNS, approver receives email, clicks approve link (which calls back to Step Functions with the token), state machine records the approval timestamp and IAM principal in SSM, then continues. Every phase gate has a full audit trail.
The ugly part - and I'm not going to pretend this is elegant - is that task tokens have a 1-year max timeout and there's no built-in retry flow. If the approval email goes to spam and nobody notices, the state machine sits in WaitForTaskToken indefinitely. It doesn't alarm by default. It just parks. You need a CloudWatch alarm on step function execution duration to catch this. The paid section covers the exact alarm configuration.
CloudFront bypass for transaction APIs
Static assets go through CloudFront normally - cache everything aggressively, let edge locations serve the React bundle. But transaction API paths (/api/v1/transactions/*, /api/v1/payments/*) carry Cache-Control: no-store, no-cache headers, which forces CloudFront to always go to origin. EventBridge cross-region event routing - architecture deep dives here
The reason this matters for compliance is subtle. If CloudFront caches a transaction response - even for 1 second - a subsequent request from a different user hitting the same edge node could theoretically get the cached response. In a fintech context that's both a data privacy problem and a correctness problem. The bypass headers prevent this entirely. You lose CloudFront's cost benefits on API traffic, but that's the right trade-off.
Decision Matrix or Worksheet Logic
Should you use this architecture? Here's the honest version of that question.
| Scenario | Recommendation |
|---|---|
| Single-region fintech, no EU users yet | Don't build this yet. Wait until you have EU users or an audit requirement. The operational overhead is real. |
| EU users but no GDPR audit deadline | Start with S3 CRR for data residency. Add Global Tables only when you need EU-region transaction processing. |
| GDPR audit deadline, existing transaction history | This pattern. Specifically the phased Step Functions approach. |
| Greenfield EU deployment, no migration needed | Simpler architecture - just deploy to both regions from the start without the weighted routing phase-in. |
| >10K TPS transaction volume | This pattern with modifications. The Global Tables replication write unit costs become significant. Paid section covers this. |
The key question to answer before you start: do you need active-active (write to either region, read from either region) or active-passive (write to us-east-1, replicate to eu-central-1 for reads and failover)? This architecture assumes active-active. If you only need active-passive - which is often enough for GDPR compliance, since you just need data to reside in the EU, not necessarily be processed there - you can simplify significantly and save real money on replication write units.
Failure and Edge Cases
The consistency gap is real and it's specific. Here's exactly how it manifests.
It's 47 hours post-cutover. Route53 has finished bleeding through the weight shift - 90% of traffic is now hitting eu-central-1. But some DNS resolvers cached the old records longer than your 60s TTL (because that's just what some resolvers do), so you're still seeing maybe 8% of requests hitting us-east-1 Lambda. That Lambda writes a transaction record to the us-east-1 DynamoDB table. Global Tables starts replicating it to eu-central-1. 180ms later, a webhook callback for that same transaction hits eu-central-1 Lambda. It reads the idempotency record. The replication hasn't landed yet. It thinks this is a new transaction. It processes it again.
The user sees one charge. Your ledger has two debit records. The EU replica's audit log has one record. The us-east-1 audit log has two. Compliance auditor asks for all transactions in the EU region for that user. Your EU audit log says one transaction. Your us-east-1 log says two. That's the finding.
The mitigation requires three things working together: conditional writes on the idempotency check (not just reads), EventBridge deduplication IDs that match the transaction ID, and a reconciliation Lambda running every 15 minutes during the 72-hour window comparing record counts between regions. The deduplication ID alone isn't enough - EventBridge dedup windows are 24 hours and don't cover the DynamoDB replication lag scenario. For cross-region observability setup that catches this, see the CloudWatch setup guide here
The S3 replication edge case is less dramatic but worth knowing. CRR is forward-only. Objects that existed in the us-east-1 bucket before you enabled replication don't get copied automatically. You need S3 Batch Replication or a Lambda-driven backfill for historical objects. The stack doesn't provision this - it's a separate runbook step, and it's easy to forget until an auditor asks for a document that was uploaded three months ago.
Operational Guidance
Day-of-cutover checklist, in order:
First - verify that Global Tables replication lag is below 500ms before you start shifting Route53 weights. Check the ReplicationLatency CloudWatch metric on the DynamoDB table. If it's elevated, stop. Don't shift traffic with a laggy replica.
Second - set your Route53 TTL to 60 seconds at least 24 hours before cutover. Don't try to change TTL and shift weights at the same time. The TTL change needs to propagate first.
Third - the Step Functions state machine should be your single control plane. Don't make manual changes to Route53 weights outside of the state machine during the migration. The state machine records what it did in SSM. Manual changes create a record mismatch that's annoying to untangle.
Fourth - wire up an alarm on EventBridge dead-letter queues before cutover, not after. The IAM least privilege configuration for cross-region operations is the most common reason events silently drop - the PutEvents permission on the target bus is easy to miss because it's a resource-based policy on the bus, not a role-based policy on the Lambda. Check this explicitly.
Fifth - X-Ray traces won't stitch across EventBridge cross-region hops automatically. You need to manually propagate the trace ID in the event payload. If you don't do this before cutover, debugging a cross-region transaction failure post-cutover means manually correlating two disconnected trace trees. It's possible. It's just miserable at 2am.
Closing Recommendation
Every service in this stack is defensible. The Global Tables setup is correct. The weighted routing is correct. The Step Functions gates are the right pattern for compliance-auditable cutover steps. But if you deploy this and walk away after the last Route53 weight hits 100%, you will hit the consistency gap within 72 hours.
What you actually need is this stack plus three additions: a reconciliation Lambda on a 15-minute schedule during the post-cutover window, conditional write semantics on every idempotency check, and CloudWatch alarms on EventBridge DLQ message count. Without those three things, you've done the hard 90% and left open exactly the gap compliance auditors are trained to find.
The paid section below covers all six trade-offs with mitigation code, the deployment sequence with bootstrap order, the cost breakdown (at 5K TPS, Global Tables replication write units alone run about $340/month in eu-central-1 - not catastrophic, but it needs to be in someone's spreadsheet), and the three alternative architectures we rejected and why.
If you're running this migration in the next 30 days, the sequencing matters as much as the code. Read the deployment section before you touch the CDK stack.
Next Step
free: You've got the full architecture picture, the three critical design decisions, and the specific consistency gap that will cause you problems. That's enough to review your own setup against this pattern and identify whether you have the same exposure.
paid: The complete CDK file walkthrough section by section, exact deployment sequence and bootstrap order across both regions (order matters - if you bootstrap eu-central-1 before setting up the Event Bus policy in us-east-1, your first deploy will fail in a confusing way), all six trade-offs with mitigation code, cost breakdown at 1K/5K/10K TPS, what breaks beyond 10K TPS, and the full analysis of Aurora Global DB, Kinesis cross-region, and manual blue-green ALB as alternatives and why each was rejected for this use case.
Members can access the full paid section above. If you're reading this on the free tier, your account page has upgrade options - this post is part of the Platform Engineering deep dive series.
Reference source code: github.com/InfraTales — production-ready cdk-ts code for this architecture.