So a client calls me a few months back - fintech, real-time payments, running out of eu-central-2 (Zurich), and they need to cut over to eu-west-1 (Ireland) before their next PCI-DSS audit window. The timeline is tight. The stack is not simple. And they want to use CDK TypeScript to codify the whole thing, which is the right call - but building aws cdk multi-region payment infrastructure from scratch with no working reference is genuinely painful. VPC peering across regions, KMS-encrypted RDS, S3 replication, Lambda-in-VPC, CloudWatch alarms - all of it in one stack. I've seen teams spend a week on this and still ship a deployment that looks green but breaks at runtime.
This post is what I wish existed before I started that engagement.
One assumption upfront: you're already sold on CDK TypeScript and you're not relitigating IaC tooling choices. This is also written for engineers who know AWS reasonably well - I'm not explaining what a VPC is.
Problem Framing
The real problem here isn't the architecture diagram. Any senior engineer can sketch this on a napkin in five minutes. The problem is that CDK's abstraction hides exactly the places where two-region deployments silently succeed in cdk deploy but break at runtime.
VPC peering routes that look correct in code but never propagate to the peer's route tables. S3 replication rules that technically get created but only activate after a second deploy cycle because versioning wasn't enabled before the rule was applied. Lambda ENI exhaustion that only surfaces when you're running real payment traffic and your on-call gets paged with ECONNREFUSED at 2am with nothing obvious in CloudWatch.
The migration context matters too. Moving from eu-central-2 to eu-west-1 isn't just a region flag change. You're standing up parallel infrastructure, running cross-region traffic during the cutover window, and doing all of it under PCI-DSS scrutiny. Requirement 8.3 wants credential rotation. Requirement 12.3 wants high availability with documented failover. Your CDK output says "✅ successfully deployed" and your auditor is about to ask you to demonstrate RDS failover in a change-controlled window.
What this post covers: when do these silent failures happen, which design decisions produce them, and what does "done" actually look like before you call the migration complete.
Architecture Overview
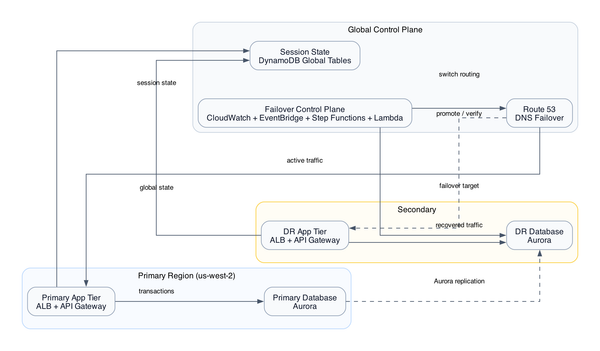
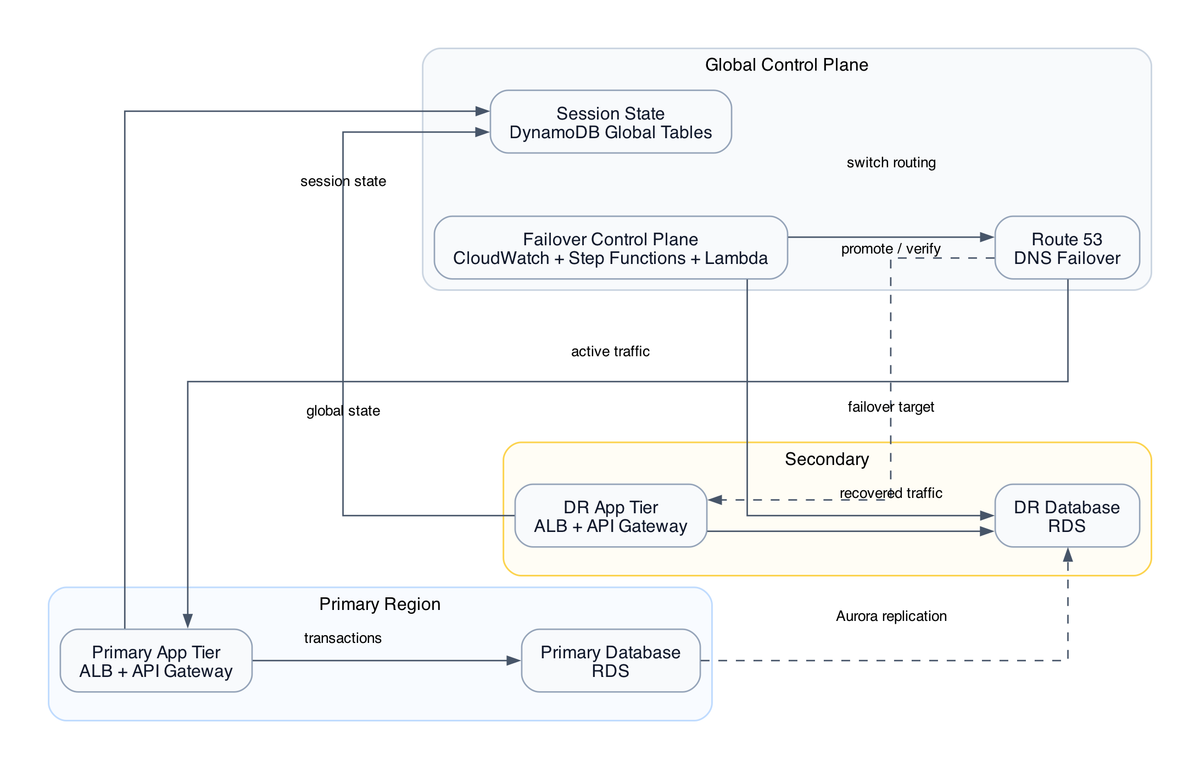
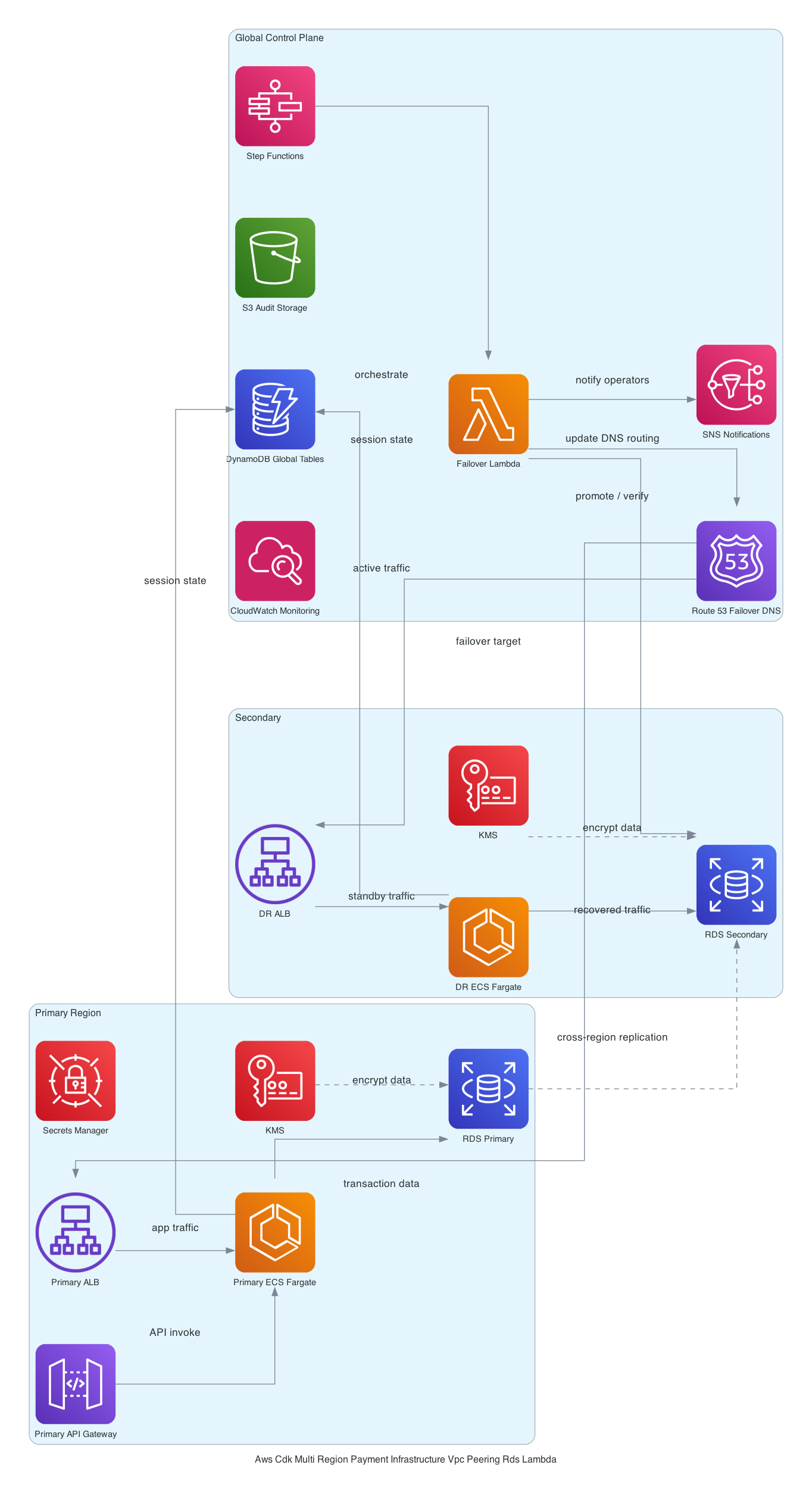
Two VPCs - 10.0.0.0/16 in eu-central-2 and 10.1.0.0/16 in eu-west-1 - peered for cross-region connectivity [from-code]. Each VPC has public subnets hosting NAT Gateways and private subnets isolating compute and data. Standard enough.
The eu-west-1 side is where everything interesting lives. An API Gateway HTTP API routes POST /payment to a Node.js 20.x Lambda. That Lambda runs inside the VPC - more on why in a second, because this decision has real consequences. It writes to a KMS-encrypted RDS PostgreSQL 17.4 Multi-AZ instance and a DynamoDB table running pay-per-request with PITR enabled [from-code]. S3 buckets in both regions with versioning and cross-region replication handle payment data durability. CloudWatch dashboards and alarms tie it together operationally [from-code].
Here's the rough picture in CDK terms - this is an illustrative excerpt, not deployable code (see the full stack in the GitHub repo below)
// VPC construct in eu-west-1 - illustrative only
const irelandVpc = new ec2.Vpc(this, 'IrelandVpc', {
ipAddresses: ec2.IpAddresses.cidr('10.1.0.0/16'),
maxAzs: 2,
natGateways: 1,
subnetConfiguration: [
{
cidrMask: 24,
name: 'Public',
subnetType: ec2.SubnetType.PUBLIC,
},
{
cidrMask: 24,
name: 'Private',
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
},
],
});
// Lambda inside the VPC for private RDS connectivity
const paymentHandler = new lambda.Function(this, 'PaymentHandler', {
runtime: lambda.Runtime.NODEJS_20_X,
vpc: irelandVpc,
vpcSubnets: { subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS },
// ... handler, code, environment
});
The non-obvious choice is Lambda inside the VPC. Let me explain why it has to be there and what it costs you.
RDS PostgreSQL is in a private subnet - as it should be for PCI-DSS. Private subnet means no public endpoint. Lambda outside the VPC can't reach it. So you either run Lambda inside the VPC to get private subnet connectivity, or you put a bastion/proxy in the public subnet (worse), or you use RDS Proxy (adds cost and complexity, potentially worth it for connection pooling at scale). For this migration timeline, Lambda-in-VPC was the call.
The cost is cold start latency. Without Hyperplane ENI (which AWS has largely addressed for non-legacy VPCs created after 2020), Lambda VPC cold starts on modern runtimes average around 500ms-1s extra [inferred]. For a payment API where p99 SLA matters, you need to decide: accept occasional cold starts, or pay for Provisioned Concurrency (~$40-80/month per 10 units [editorial]). Those are two separate decisions. Don't conflate them.
Deep Analysis
Here's where I want to spend real time. Three design decisions where the reasoning isn't obvious.
Why DynamoDB alongside RDS?
I get this question every time. "You already have Postgres, why DynamoDB?" Two reasons. First, payment event sourcing - you want an append-only log of every payment attempt, status transition, and webhook delivery that survives even if the RDS instance has a bad moment. DynamoDB with PITR is very good at being the thing that's always available. Second, idempotency keys. You do not want idempotency key lookups going through a Multi-AZ RDS failover window. Put them in DynamoDB, keep your idempotency logic fast and resilient.
Pay-per-request billing is correct for this stage. But [editorial]: at roughly 200+ sustained WCU, provisioned capacity becomes cheaper. A growing payment startup can hit that threshold within months. Set a billing alarm before you hit that number, not after.
Why S3 replication instead of something fancier?
The eu-central-2 bucket exists because the client had historical transaction data and reporting pipelines pointing at that region. Cross-region replication keeps the Ireland bucket as the primary write target while the Zurich bucket stays populated for the old reporting stack. Clean migration, no big-bang cutover for the data layer.
The catch: S3 replication is asynchronous. There is no guaranteed lag ceiling under heavy write load [from-code]. If you treat the eu-central-2 replica as a real-time DR target, you are building on an assumption that can fail you. Monitor ReplicationLatency in CloudWatch. Set an alarm at 15 minutes. This is not optional.
Also - and this one bit us - S3 versioning must be enabled on the source bucket before the replication rule is applied. CDK creates both in the same cdk deploy run. If there's no explicit dependency order forcing versioning to be active before the replication config is attached, you can end up with a replication rule that exists in the console but isn't actually replicating anything. CDK won't tell you. The deploy succeeds. You find out when you check the bucket two days later.
The VPC peering problem that nobody talks about
CDK will create the peering connection. It will add routes to your route tables. In code, it looks correct. But CDK does not automatically propagate new subnet CIDRs to the peer VPC's route tables when you update your VPC topology later [from-code]. Add a subnet in Ireland, forget to update the Zurich route table, and you now have a connectivity break that shows up as a timeout - not a DNS failure, not a clear network error. A timeout. At 2am.
The operational discipline here is to treat the route tables as a living document with a checklist item on every VPC topology change, not a one-time CDK output.
If you want to go deeper on the cross-region stack deployment patterns that make this more manageable, there's a good reference over at CDK cross-region stack deployment patterns.
Decision Matrix
| Decision | What we chose | Acceptable alternative | When to switch |
|---|---|---|---|
| Lambda cold starts | Accept + monitor p99 | Provisioned Concurrency | If p99 > SLA threshold consistently |
| DynamoDB billing | Pay-per-request | Provisioned | At ~200+ sustained WCU |
| RDS HA | Multi-AZ | Single-AZ | Never, for PCI-DSS Req 12.3 |
| NAT Gateway | One per region | VPC Endpoints for AWS services | When NAT data costs exceed ~$50/month |
| S3 replication lag monitoring | CloudWatch alarm at 15min | Custom Lambda lag checker | If SLA tightens below 15min RPO |
| Lambda placement | Inside VPC | RDS Proxy + Lambda outside VPC | At high concurrency needing connection pooling |
Failure Modes
These are the ones I've either seen happen or can walk you through the exact failure sequence. Not hypotheticals.
ENI exhaustion in the Lambda private subnet. Your private subnets are /24 - that's 251 usable IPs. Lambda allocates ENIs from that pool. Each Lambda function needs at least one ENI, and at concurrency spikes it needs more. Add multiple Lambda functions sharing the same subnet, add CodeDeploy deploying new versions that hold old ENIs during draining - you can run out of IPs. The failure mode: invocations error with ECONNREFUSED. CloudWatch shows Lambda errors but not why. There's no automatic capacity alarm. You find out when payments stop processing [inferred].
Fix: either use a dedicated /23 or larger subnet for Lambda, or set a CloudWatch metric alarm on AvailableIPAddressCount for the private subnet. Add this alarm. It's two lines of CDK.
KMS key policy drift or accidental disable. If someone with KMS access disables the key or the key policy gets updated to remove the RDS role's kms:Decrypt permission, RDS can no longer decrypt its storage. The database goes into a read-lock state. You can't recover without re-enabling the key - but if the key is scheduled for deletion (default 7-30 day window), the clock is ticking [inferred]. Set an explicit deletion window guard. Log all KMS key state changes to CloudTrail. Wire a CloudWatch alarm on KMSKeyDeletion and KMSKeyDisabled events.
For more on building KMS key policies that don't quietly break your RDS, see KMS key policy patterns for RDS encryption.
S3 replication silently not running. Covered above, but worth repeating: if versioning and the replication rule are applied in the same CDK stack without explicit addDependency() ordering, replication may never activate. The bucket exists, the rule exists in the console, but ReplicationLatency metrics never appear because no objects are actually being replicated. After deploy, immediately run aws s3api get-bucket-replication against both buckets and validate the config is live. Treat this as a smoke test, not an assumption.
CloudWatch alarms that don't page anyone. I'll say this plainly: if your alarm actions aren't wired to an SNS topic connected to PagerDuty, OpsGenie, or at minimum an email that someone actually reads, your monitoring is theater [inferred]. A dashboard nobody looks at at 2am is not monitoring. Wire the alarms in CDK. Don't leave this as a "we'll add it later" task.
Operational Guidance
A few things I'd tell a new engineer taking ownership of this stack.
RDS password rotation is not optional for PCI-DSS. Requirement 8.3 is explicit. If your DB credentials are a static secret in SSM Parameter Store or - worse - in an environment variable, you will fail the audit. Use Secrets Manager with automatic rotation. CDK has an aws-cdk-lib/aws-rds construct that supports this natively through credentials: rds.Credentials.fromGeneratedSecret(). Use it from day one [editorial].
Test cross-region connectivity before you call the migration done. A green cdk deploy output is a provisioning receipt, not a correctness guarantee. Write a smoke test that actually sends a POST /payment request through API Gateway, confirms the Lambda wrote to RDS and DynamoDB, and checks that the S3 object landed in both the eu-west-1 bucket and the eu-central-2 replica within your expected lag window. Run this test from outside AWS, pointed at the production stack, before you flip DNS.
Know your cost baseline. Two NAT Gateways at ~$32/month each. RDS Multi-AZ adds ~$150-200/month over single-AZ. NAT data processing at $0.045/GB means cross-region Lambda egress through NAT will quietly accumulate as transaction volume grows. At 50 TPS it's manageable. At 500 TPS you'll want to move internal AWS service calls (S3, DynamoDB, SSM) to VPC Endpoints and stop routing them through NAT. The full breakdown is available in the GitHub repo for this architecture.
VPC peering runbook. Your on-call runbook must explicitly cover "peering connection dropped" as a scenario. There is no automatic reroute. The runbook should cover: how to verify peering connection state in both regions, how to verify route table entries in both VPCs, and who has permission to add/update routes in an incident window.
Next Step
Accept this pattern if: you're doing a time-boxed regional migration, your team knows CDK TypeScript, and you need PCI-DSS controls stood up without designing a multi-region architecture from scratch. The Lambda-in-VPC + RDS + DynamoDB combination is well-understood, auditable, and gets you to a defensible PCI posture faster than most alternatives.
Reject this pattern if: you're at high enough transaction volume that RDS connection pooling is already a concern (look at Aurora Serverless v2 + RDS Proxy instead), or if your RPO for the cross-region DR scenario is measured in seconds rather than minutes (S3 async replication won't meet that, and you'll need a different data replication approach).
free: Everything in this post - the architecture reasoning, design decisions, failure modes, and operational guidance.
paid: The complete deployable CDK TypeScript stack (VPC peering with automated route table propagation, KMS key policy with deletion window guard, S3 replication IAM role, Lambda ENI subnet sizing, CloudWatch alarms wired to SNS), the two-region deployment sequence that avoids CDK cross-region stack dependency limits, per-service cost breakdown at 50 TPS and 500 TPS, and a failure mode reference table with exact recovery steps.
Get the full stack - members only
Tags: aws-architecture, networking, multi-region, cdk-ts, #type-pattern
Reference source code: github.com/InfraTales — production-ready cdk-ts code for this architecture.