Running Lambdas in private subnets without NAT Gateways is one of those ideas that sounds risky until you actually understand what aws cdk lambda vpc endpoints no nat gateway means in practice - and then it sounds obvious. The catch is that "obvious" architectures have the most subtle failure modes. This one has a particular failure mode that will ruin your night, and I want to talk about that before I talk about the pattern itself.
Last year I was helping a team debug a pipeline where every health check was green, every security group looked right, and their Document Processor Lambda was just... silently timing out. No errors. No alarms. Just requests going into a black hole at around 2 AM on a Tuesday after a routine CDK deployment. Took us about an hour to find it. The route table entry for their S3 Gateway endpoint had been quietly replaced during a stack update. That's the thing about Gateway endpoints - they live in route tables, not ENIs. When the route goes missing, nothing screams. Everything just stops.
That's the context here. We're going to walk through a four-stack CDK document ingestion pipeline that uses S3 and DynamoDB Gateway endpoints plus an API Gateway Interface endpoint to keep Lambdas in fully isolated private subnets - zero NAT Gateways, zero per-GB data charges - and I'm going to be honest about exactly where this pattern works, where it breaks, and what you need to monitor so you're not the one debugging it at 2 AM.
Who Is This Pattern For

This pattern is for platform engineers and senior backend developers building document ingestion APIs - think KYC uploads, contract submissions, compliance file intake - who need to satisfy three constraints at once: their security team wants Lambdas in private subnets, their finance team is asking about that $130/month NAT Gateway line item, and their compliance team needs audit trails on every document that enters the system.
If you've never had to justify a NAT Gateway cost to a finance team, or if your security team has never asked "wait, why does that Lambda need internet access?", this might be more architecture than you need right now. But if those conversations sound familiar, keep reading.
You should be comfortable with CDK TypeScript, understand what VPC subnets and route tables actually do (not just conceptually - you should know what a route table entry looks like), and have at least one prior Lambda deployment that made you think "there has to be a cleaner way to handle authentication than this."
Problem the Pattern Solves
The naive document upload flow breaks the moment you need it to actually work in production. You know the one: pre-signed S3 URL, client uploads directly, Lambda picks up the S3 event, done. Except - who authorized that client? How do you audit which client sent which document? What happens when the Lambda fails? Where does the file go? Does your security team know there's a Lambda in a public subnet making calls to S3 over the internet?
Every "simple" piece of this has a production requirement hiding behind it. API authentication your security team will actually sign off on. Audit trails compliance can query. Event-driven processing with failure capture. And all of it needs to run without paying $65-130 per AZ per month for NAT Gateways that mostly just route bytes between your Lambda and AWS services that have cheaper endpoints available.
This pattern solves exactly that. Documents enter through an API Gateway endpoint with Lambda Authorizer-based API key validation. They land in an encrypted S3 bucket. A Document Processor Lambda picks them up, writes metadata to DynamoDB. DynamoDB Streams fan out to a Notification Lambda for downstream status. A Dead Letter Queue catches processing failures. None of that traffic touches a NAT Gateway - because it doesn't need to.
Context and Scale Assumptions
This pattern is sized for moderate document ingestion workloads - hundreds to low thousands of documents per day, not millions. The Lambda Authorizer approach with DynamoDB key validation works well here, but at very high request rates you'll start feeling it in both latency and read capacity costs.
The design assumes you're deploying into a single AWS region (I'll call out the multi-region implications in the failure edges section). It also assumes your document processing is fully contained within AWS services - no third-party virus scanning APIs, no external webhook callbacks, no validation services that live outside your VPC. This is a hard boundary in the zero-NAT design. [inferred]
We're also assuming CDK TypeScript and CloudFormation as the deployment mechanism, which matters because the cross-stack reference behavior is CloudFormation-specific and creates deployment sequencing constraints you need to be aware of.
System Boundaries and Request Flow
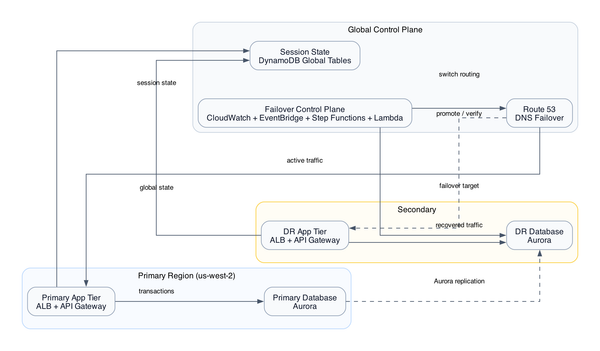
Four CDK stacks. That's the shape.
NetworkingStack is the foundation - VPC, private subnets, security groups, and critically, the Gateway endpoint route table entries for S3 and DynamoDB, plus the Interface endpoint for API Gateway. Everything else depends on this stack existing first.
StorageStack creates the encrypted S3 document bucket and the DynamoDB tables - one for API key storage (used by the authorizer), one for document metadata with Streams enabled. The S3 bucket is configured to trigger Lambda on object creation. [from-code]
ComputeStack is where the Lambdas live - the Lambda Authorizer, the Document Processor, and the Notification Lambda. All three run in private subnets with no internet access. Their only outbound routes are through the VPC endpoints established in NetworkingStack. [from-code]
ApiStack wires it together - API Gateway with the Lambda Authorizer attached, routes configured to accept document uploads, and the Interface VPC endpoint making the API callable from within the VPC. A parent TapStack pulls all four together and handles the cross-stack wiring.
The request flow: client sends a document upload request to API Gateway. API Gateway calls the Lambda Authorizer, which queries DynamoDB to validate the API key. If valid, the request proceeds. The API handler Lambda writes the document to S3. S3 triggers the Document Processor Lambda via event notification. Document Processor writes metadata to DynamoDB. DynamoDB Streams trigger the Notification Lambda for downstream status updates. If Document Processor fails, the event goes to the Dead Letter Queue. All Lambda-to-AWS traffic routes through VPC endpoints - no NAT Gateway anywhere in this path. [from-code]
Why This Shape Over Alternatives
This is the part I actually want to talk about, because the tradeoffs here are real and the "just use a NAT Gateway" crowd isn't wrong - they're just not paying attention to the bill.
The zero-NAT-Gateway choice saves roughly $65-130 per AZ per month depending on your region and data transfer volume. $54/month just for the NAT Gateway itself before you count per-GB charges. For a document pipeline running in 2 AZs, that's potentially $260/month you're not spending. Over a year, that's real infrastructure budget.
But - and this is a real but - Gateway endpoints for S3 and DynamoDB are not the same thing as Interface endpoints. Gateway endpoints inject a route table entry. They don't create an ENI. That means they're free with no per-GB cost, which is great. It also means that if something modifies your route table, the endpoint silently disappears. More on this in the failure edges section.
I went with a Lambda Authorizer over Cognito for one specific reason: the team needed to issue short-lived API keys to external clients and revoke them quickly without managing Cognito user pools for what are essentially service-to-service integrations. DynamoDB key storage with a 300-second authorizer cache gives you reasonably fast revocation (worst case 5 minutes) with acceptable latency overhead. If you need sub-minute revocation, this tradeoff doesn't work for you - check how Lambda authorizer caching trade-offs affect your specific requirements.
Four separate stacks over a monolithic stack because these components have genuinely different deployment lifecycles. Network topology changes rarely. Storage schema changes occasionally. Compute code changes frequently. Separating them means a Lambda deployment doesn't require CloudFormation to re-evaluate your VPC configuration.
Failure Edges
Let me be specific about the things that will actually go wrong.
The route table failure. This is the one that started this whole post. If CDK replaces a subnet's route table during an update - maybe you changed a subnet parameter, maybe there's a drift correction - the Gateway endpoint route table entries don't automatically transfer. Every Lambda call to S3 and DynamoDB starts timing out with a generic connection error. Nothing in CloudWatch says "your Gateway endpoint route is missing." You have to know to look at the route table. [inferred]
The authorizer throttle masquerade. If the DynamoDB table backing your Lambda Authorizer gets throttled during a traffic spike, API Gateway returns 500 to clients. Not 429 - 500. It looks exactly like an application crash. Your on-call will spend 30 minutes ruling out everything else before someone thinks to check the Authorizer function's DynamoDB read metrics. [editorial]
The S3 event drop. Dead Letter Queues catch Lambda execution failures. They do not catch S3 event delivery failures. If your Document Processor Lambda is throttled at the concurrency limit, S3 retries for up to 6 hours and then silently drops the event. No DLQ entry. No alarm unless you're explicitly monitoring S3 event delivery success metrics. I'm not joking when I say this one is invisible by default. [editorial]
The duplicate notification. DynamoDB Streams gives you at-least-once delivery. Under retry conditions, your Notification Lambda will process the same stream record twice. If it's not idempotent, you'll generate duplicate notifications. This is a guarantee, not a risk. Build for it. We've got a deeper writeup on handling DynamoDB Streams at-least-once delivery safely.
The KMS/CloudWatch Logs thing. If you're encrypting CloudWatch Logs with KMS (and you should be), you must explicitly grant logs.us-east-1.amazonaws.com the necessary KMS permissions in your key policy. CDK does not do this automatically. Your Lambdas will deploy fine and then fail to write logs. This is the single most common "why is there nothing in CloudWatch" failure I've seen in setups like this. (Don't ask how long this took me the first time.) [editorial]
Observability and Operations
Standard Lambda error rate alarms are not enough here. Here's what you actually need.
Monitor the Gateway endpoint route table entries. I know that sounds paranoid - after that 2 AM incident, I don't care. Set up a Config Rule or a CloudWatch Events rule that fires when route table associations change. Treat a missing Gateway endpoint route the same way you'd treat a missing security group rule.
Add DynamoDB read capacity alarms on the Authorizer table specifically. Not just on the document metadata table - on the authorizer table. That's the one that takes down your API when it gets throttled.
Set p99 duration alarms on all three Lambdas, not just error rate alarms. A Lambda that's consistently hitting 4 seconds on a 300ms operation is a Lambda that's about to start failing - you want to know before it crosses into failure territory.
Monitor S3 event notification delivery metrics. They're in CloudWatch under the S3 namespace. NumberOfNotifications vs NumberOfSuccessfulNotifications. The gap between those two numbers is documents your pipeline will never see.
And explicitly alarm on DLQ message counts. A message in your DLQ at 3 AM means a document didn't process. That should wake someone up.
Cost Drivers
Here's the actual math. [inferred]
NAT Gateway (2 AZ): $65-130/month saved by using Gateway endpoints.
API Gateway Interface VPC endpoint (2 AZ): ~$32/month. This is the cost of keeping your API callable from inside the VPC without internet exposure. Unavoidable if you need VPC-internal API access.
Lambda Authorizer DynamoDB reads: At 300-second cache TTL with moderate traffic, this is low - maybe $2-5/month. Without caching, it scales linearly with request volume and becomes the dominant compute cost fast.
DynamoDB for document metadata: Pay-per-request mode for this workload, probably $5-20/month depending on document volume.
S3 storage: Entirely workload-dependent, but per-request costs for document ingestion at this scale are negligible.
Total infrastructure overhead for this pattern: roughly $50-80/month excluding Lambda execution and S3 storage. Compare that to $65-130/month just for NAT Gateways before any data transfer charges. At any meaningful scale, this pattern wins on cost.
When Not to Use It
Don't use this pattern if your document processing requires calling any non-AWS external service. Virus scanning APIs, SWIFT validation endpoints, third-party OCR services - any of these require either adding Interface VPC endpoints (for AWS services) or accepting that you need internet access, which means a NAT Gateway or redesigning the flow. The zero-NAT constraint is a hard boundary, not a preference. [inferred]
Don't use it if you need sub-minute API key revocation. The 300-second authorizer cache is the right default for the latency tradeoff, but a revoked key stays valid for up to 5 minutes. For most document ingestion use cases that's fine. For anything involving real-time access control decisions, it's not.
Don't use it if you're running this across multiple regions without thinking carefully about the cross-stack export dependencies. The four-stack pattern creates CloudFormation export relationships that become painful to modify under multi-region rollout constraints. Plan your stack boundaries before you deploy into production.
And honestly - if your team hasn't operated Gateway endpoint route table entries before and you don't have monitoring in place to detect a missing route, don't use the zero-NAT variant yet. Add the NAT Gateway, get comfortable with the rest of the pattern, and migrate off it once your observability is solid. A NAT Gateway you understand is better than a Gateway endpoint you don't.
Next Step
This pattern is the right call if you're building a document ingestion pipeline that needs private Lambda execution, real API authentication, and cost-efficient AWS service routing - and your team is prepared to monitor route table state with the same seriousness as compute health.
It's the wrong call if you have external service dependencies in your processing flow, if you need instant key revocation, or if your team is newer to VPC endpoint operations and doesn't yet have the observability to catch a silent route table change.
free: The architecture diagram, the four-stack breakdown, VPC endpoint strategy (Gateway vs Interface), and the NetworkingStack CDK snippet showing VPC and security group configuration are all in the post above.
paid: Complete CDK TypeScript for all four stacks including Lambda Authorizer logic and DynamoDB key validation, deployment sequencing guide to avoid cross-stack export conflicts, the exact KMS key policy fix for CloudWatch Logs encryption, cost comparison spreadsheet (this design vs. NAT Gateway alternatives), the S3 event delivery monitoring setup, and the authorizer throttle detection runbook. Join InfraTales to get access.
If you're also thinking about how VPC endpoint route table monitoring fits into a broader observability strategy for multi-stack CDK deployments, that's worth reading before you deploy this to production.
Reference source code: github.com/InfraTales — production-ready aws-cdk-typescript code for this architecture.