Building a Petabyte-Scale Log Analytics Platform on AWS
A petabyte-scale log analytics platform built on AWS using OpenSearch, S3, Kinesis, and Firehose. It delivers real-time search, long-term storage, and cost-efficient observability. Designed with Terraform IaC for high scalability, security, and enterprise readiness.


In modern distributed systems, logs are more than just debugging artifacts - they are the lifeblood of observability. As organizations scale into hundreds of microservices, millions of events per second, and multi-region architectures, traditional logging stacks struggle to keep up.
That’s where a Petabyte-Scale Log Analytics Platform becomes essential.
In this post, we break down a production-grade architecture built using:
- Amazon S3 as an infinitely scalable data lake
- OpenSearch for fast, real-time search
- AWS serverless + managed services for cost-efficient ingestion
- Terraform for complete Infrastructure-as-Code
This blog is based on the project “log-analytics-petabyte-scale”, which provides the foundation for an enterprise-grade log analytics solution.
Why Build Log Analytics at Petabyte Scale?
Modern organizations need to analyze logs for:
- Real-time monitoring
- Security events and threat detection
- Compliance audits
- Troubleshooting production issues
- Business analytics (KPIs hidden in logs)
But storing logs in traditional databases becomes expensive and slow.
So we combine:
- Hot tier: OpenSearch → fast search
- Cold tier: Amazon S3 → cheap long-term storage
This architecture allows you to Search today’s logs in milliseconds, and search last year’s logs for pennies.
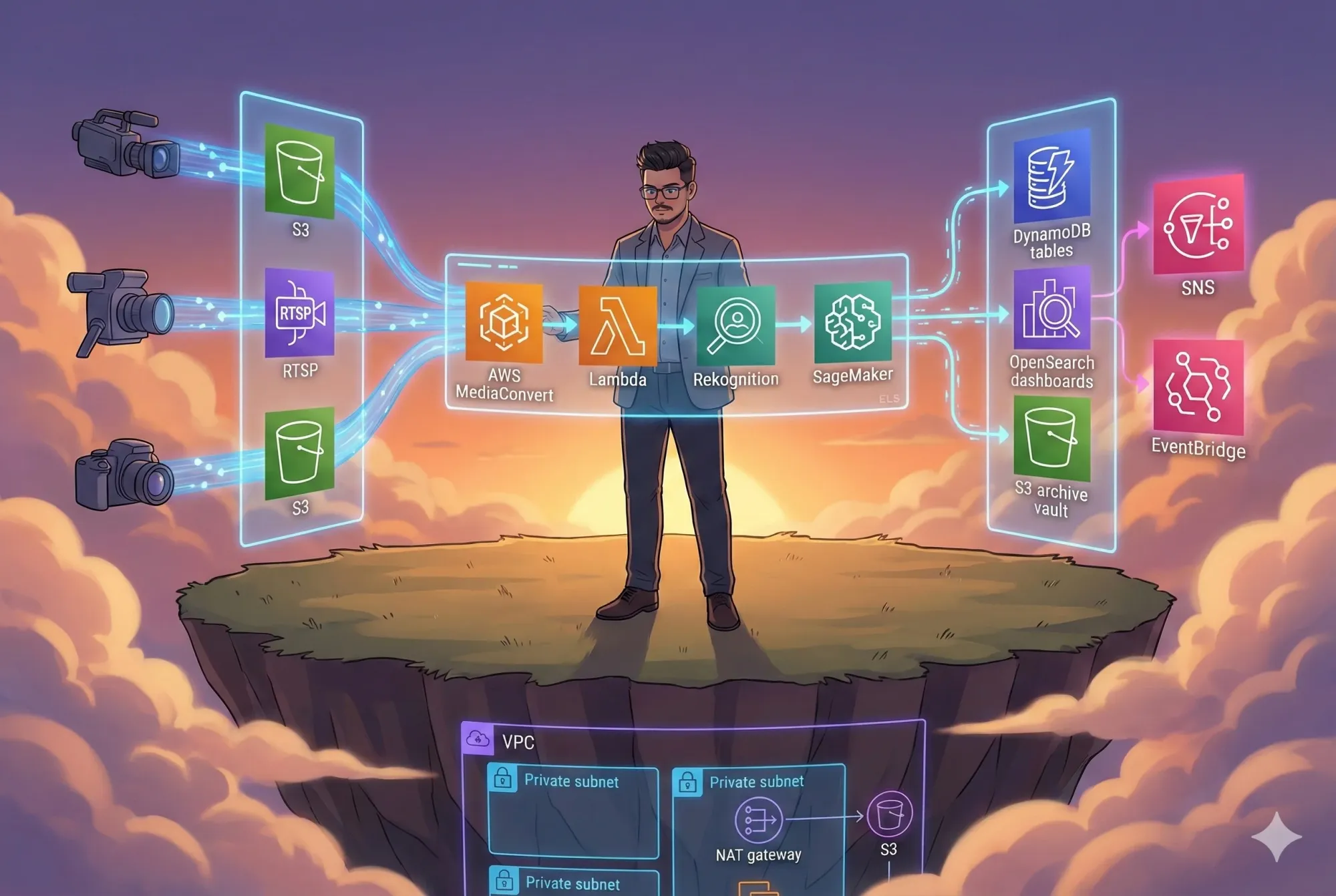
High-Level Architecture
Let’s start with the macro view - how logs flow from applications to storage and analytics tools.
High-Level Diagram

This architecture separates real-time search from long-term retention, keeping the system fast and cost-efficient.
Component Breakdown (Explained Simply)
1. Log Ingestion Layer
Logs originate from microservices, servers, containers, or on-prem systems.
Tools like FluentBit, Filebeat, or CloudWatch Logs forward them to:
→ Kinesis Data Streams
- Handles millions of log events per second
- Fully managed
- Durable and fault-tolerant
→ Firehose Delivery Stream
- Optional transformation (JSON → structured logs)
- Batching & compression (GZIP, Parquet)
- Automatic delivery to S3 and OpenSearch
2. S3 Data Lake - The Heart of Long-Term Storage
S3 acts as the ultimate log archive.
Benefits:
- Infinite scalability
- Lifecycle policies (move data to Glacier after X days)
- Cheap ($0.021/GB → Petabyte storage for low cost)
- Searchable Snapshots integrate directly with OpenSearch
S3 Folder Structure Example:
s3://logs-bucket/
raw/
year=2025/month=01/day=28/
processed/
year=2025/month=01/day=28/
archive/
3. OpenSearch - Real-Time Log Search
OpenSearch gives you:
- Fast querying
- Kibana-style dashboards
- Full-text search
- Aggregation analytics
To manage petabytes cost-effectively, we use tiered storage:
Hot Tier: SSD-backed nodes (fast, expensive)
Warm Tier: Slower storage nodes
Cold Tier: Searchable snapshots stored in S3
This drastically reduces cost while keeping all data searchable.
4. Athena + Glue - SQL on Top of S3
For historical analysis:
- Glue crawlers create table metadata
- Athena queries logs directly in S3
- No servers, no clusters, no maintenance
Example queries:
SELECT *
FROM logs_processed
WHERE status = '500'
AND service = 'payment-service'
AND date >= current_date - interval '30' day;
This complements OpenSearch by providing long-range, cost-efficient analytics.
5. Infrastructure as Code - Terraform
Your project contains the Terraform skeleton that will eventually create:
- S3 buckets
- OpenSearch cluster
- Kinesis + Firehose
- IAM roles
- VPC networking
- Monitoring & alerts
Terraform ensures:
- Repeatable deployments
- Multi-environment support (dev, staging, prod)
- Version-controlled infrastructure
- Easy rollback and upgrade paths
Putting It All Together
Here’s the full flow in a clean, simple way:
Data Flow Diagram

This sequence shows the step-by-step lifecycle of log data from generation, ingestion, routing, indexing, and storage, to historical querying through Athena.
Why This Architecture Works at Petabyte Scale
| Challenge | Solution |
|---|---|
| Logs grow without limit | S3 infinite storage |
| Hot search is expensive | Tiered OpenSearch nodes |
| Old logs rarely queried | Move to cold tier / Glacier |
| Real-time search required | OpenSearch Hot Tier |
| Historical search needed | Athena + Glue |
| Data retention requirements | S3 lifecycle policies |
Cost Optimization Strategies
- Use S3 Intelligent-Tiering for dynamic savings
- Move logs from hot → warm → cold → frozen tiers
- Batch logs in Firehose (reduces OpenSearch cost)
- Compress logs using GZIP or Parquet
- Use ARM instances (Graviton) for OpenSearch
- Offload historical queries to Athena
This architecture is built to be scalable, fast, and budget-friendly.
Current Status of the Project
- README contains complete conceptual design
- Terraform project is initialized
- Documentation placeholders are ready (ARCHITECTURE.md, SECURITY.md, etc.)
- Next step: Implement infrastructure modules
The project is intentionally starting as a blueprint, meant to expand into a full enterprise-ready platform.
What’s Coming Next?
Over the next iterations, this project will add:
- Terraform modules for all major components
- Automated ingestion pipeline
- Monitoring + dashboards
- Security hardening
- CI/CD pipeline for infra deployments
- End-to-end samples and test logs
If you follow this architecture, you’ll be able to build your own high-throughput, petabyte-scale log analytics platform on AWS.
Final Thoughts
Building a logging platform at petabyte scale is no longer optional - it’s a requirement for modern cloud-native systems. The combination of OpenSearch, S3, Kinesis, and serverless compute provides an elegant and powerful solution.
This project is the groundwork for an enterprise-class observability platform:
- Scalable
- Cost-efficient
- Secure
- Built entirely on AWS managed services
- 100% Infrastructure-as-Code
As the Terraform implementation evolves, this platform will become a complete production-ready solution.
Official References & Documentation
🔗 Amazon S3 - https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html
🔗 S3 Lifecycle Policies - https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
🔗 OpenSearch Service - https://docs.aws.amazon.com/opensearch-service/latest/developerguide/what-is.html
🔗 OpenSearch Dashboards - https://docs.aws.amazon.com/opensearch-service/latest/developerguide/dashboards.html
🔗 Searchable Snapshots (S3) - https://docs.aws.amazon.com/opensearch-service/latest/developerguide/searchable-snapshots.html
🔗 Amazon Kinesis Data Streams - https://docs.aws.amazon.com/streams/latest/dev/introduction.html
🔗 Kinesis Firehose - https://docs.aws.amazon.com/firehose/latest/dev/what-is-this-service.html
🔗 Firehose S3 Delivery - https://docs.aws.amazon.com/firehose/latest/dev/basic-deliver.html
🔗 AWS Glue Crawlers - https://docs.aws.amazon.com/glue/latest/dg/add-crawler.html
🔗 Amazon Athena - https://docs.aws.amazon.com/athena/latest/ug/what-is.html
🔗 Amazon DynamoDB - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Welcome.html
🔗 Amazon CloudWatch Logs - https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
🔗 AWS IAM - https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html
🔗 AWS KMS Encryption - https://docs.aws.amazon.com/kms/latest/developerguide/overview.html
🔗 AWS Terraform Provider - https://registry.terraform.io/providers/hashicorp/aws/latest/docs
Repository Details
👉 GitHub Repository:
https://github.com/infratales/log-analytics-petabyte-scale
GitHub - InfraTales/log-analytics-petabyte-scale
Contribute to InfraTales/log-analytics-petabyte-scale development by creating an account on GitHub.
Author
Rahul Ladumor
Platform Engineer • AWS | DevOps | Cloud Architecture
🌐 Portfolio: https://acloudwithrahul.in
💼 GitHub: https://github.com/rahulladumor
🔗 LinkedIn: https://linkedin.com/in/rahulladumor
📧 Email: rahuldladumor@gmail.com
Rahul Ladumor - ASTM International | LinkedIn
👋 Hey, I'm Rahul, AWS Community Builder, three-time certified, and the guy start-ups… · Experience: ASTM International · Education: Indian Institute of Technology, Roorkee · Location: Surat · 500+ connections on LinkedIn. View Rahul Ladumor’s profile on LinkedIn, a professional community of 1 billion members.

rahulladumor - Overview
Experienced Senior Software Developer & Architect with a passion for AWS & DevOps | Nodejs Expert | AWS Community Builder - rahulladumor

Gituhb