Building a Scalable Knowledge Graph with AWS Neptune and Pulumi
A deep dive into designing and deploying a production-ready graph database infrastructure for relationship modeling, fraud detection, and recommendation systems.

1. The Problem
Traditional relational databases struggle with complex relationship queries.
Think about fraud detection in financial systems. You need to find patterns like "find all accounts that share the same device, IP address, or phone number within the last 30 days." In SQL, that's multiple joins across several tables. Response time? Minutes. Maybe longer. Or consider recommendation engines. You want to suggest products based on what similar users bought. Again, complex joins. Slow queries. Frustrated users. Graph databases solve this. They treat relationships as first-class citizens. Queries that take minutes in SQL take milliseconds in a graph database.
AWS Neptune is Amazon's managed graph database service. It supports both property graphs (Gremlin) and RDF graphs (SPARQL). Zero server management. Automatic backups. Multi-AZ replication. But setting up production-grade infrastructure is hard. You need VPCs, security groups, monitoring, disaster recovery, cost controls. That's where Infrastructure as Code comes in.
This project builds production-ready Neptune infrastructure using Pulumi and Python.
2. What We Built
This is a Pulumi-based infrastructure framework for deploying AWS Neptune graph databases.
The design focuses on production requirements: high availability across multiple availability zones, automated monitoring and alerting, security best practices with VPC isolation and encryption, cost optimization through right-sized instances, and full automation through Infrastructure as Code.
The project provides a foundation for building knowledge graphs, fraud detection systems, recommendation engines, and any application that needs fast relationship queries.
It's designed to be extended. The core infrastructure is templated. You add your graph schema and application logic on top.
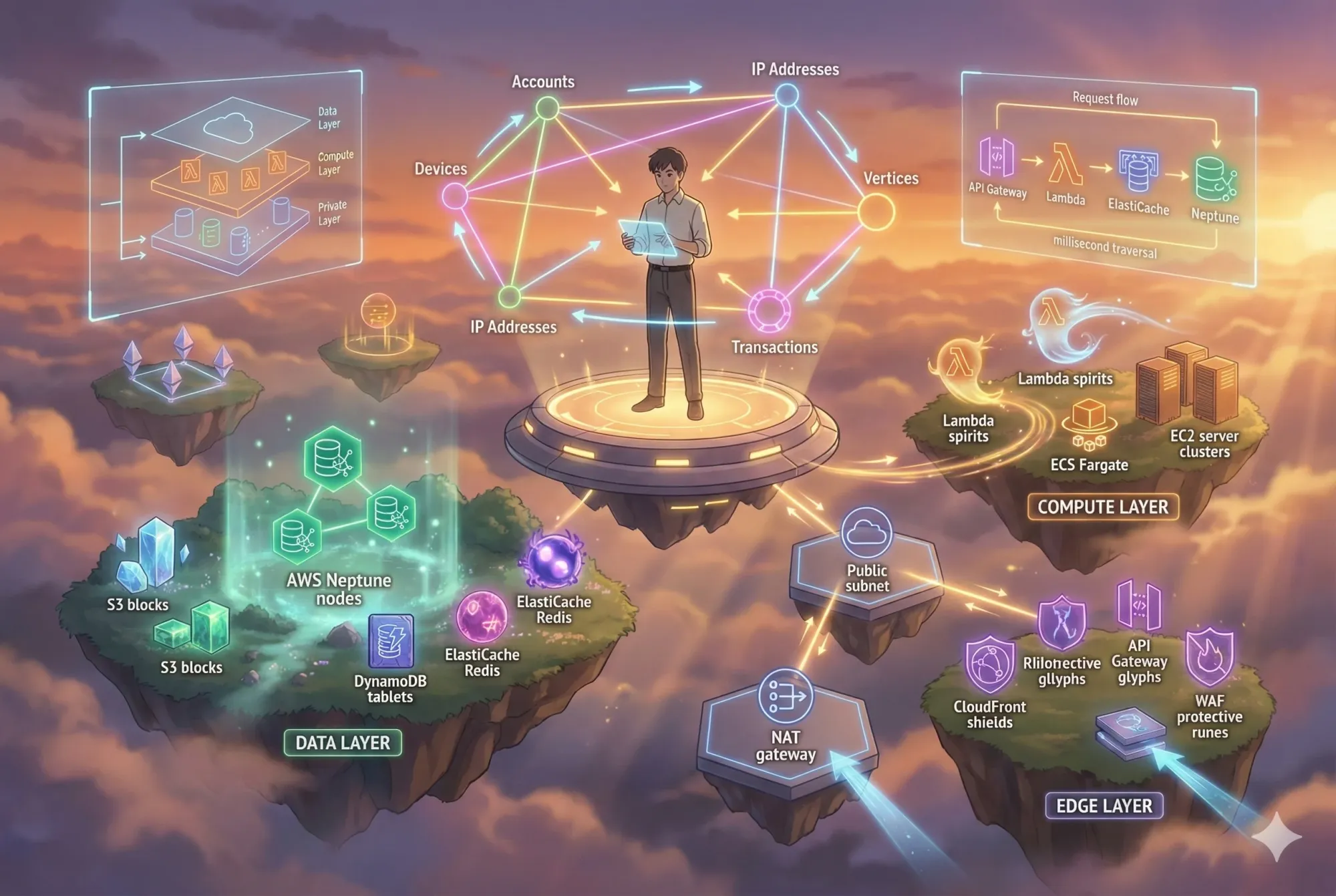
3. Architecture Overview
Core Components
Compute Layer: Lambda functions for serverless processing, ECS Fargate for containerized applications, and EC2 auto-scaling groups for compute-intensive workloads.
Data Layer: Neptune graph database as the primary data store, S3 for object storage and backups, DynamoDB for metadata, and ElastiCache for caching frequent queries.
Edge Layer: API Gateway for REST/GraphQL endpoints, CloudFront CDN for edge caching, and AWS WAF for protection against common web exploits.
Observability: CloudWatch for metrics and logs, X-Ray for distributed tracing, and SNS for alerting.
Network Architecture
The infrastructure uses a three-tier VPC design.
Public subnets (10.0.1.0/24, 10.0.2.0/24) host NAT gateways and internet-facing load balancers. Private subnets (10.0.11.0/24, 10.0.12.0/24) run application workloads with no direct internet access. Database subnets (10.0.21.0/24, 10.0.22.0/24) isolate Neptune clusters.
All subnets span two availability zones (us-east-1a, us-east-1b) for high availability.
Traffic flows through an Internet Gateway to public subnets, then through NAT gateways to private subnets. Database subnets have no internet access at all.
Data Flow
Requests hit API Gateway or CloudFront first. Authentication happens via IAM or Cognito tokens.
The compute layer checks ElastiCache for cached results. On cache miss, it queries Neptune directly using Gremlin or SPARQL.
Fresh data gets written back to the cache with a TTL. All queries generate metrics sent to CloudWatch.
If error rates spike or latency exceeds thresholds, SNS sends alerts via email or Slack.
Design Tradeoffs
Why Neptune over Neo4j? Neptune is fully managed. No server patching, no backup scripts, no cluster management. The trade-off is less control over query optimization and no native Cypher support (though you can use openCypher).
Why multi-AZ? Automatic failover. If one AZ goes down, Neptune promotes a read replica in another AZ within seconds. The cost is roughly double, but downtime is far more expensive.
Why three subnet tiers? Defense in depth. Compromising a web server doesn't give access to the database. Each tier has separate security groups and network ACLs.
Why Pulumi over Terraform or CDK? Personal preference. Pulumi uses real Python, not HCL or TypeScript CDK constructs. Better IDE support. Easier testing. The ecosystem is smaller than Terraform though.
System Architecture Diagram

Microservices Architecture Diagram

Use Case Diagram

Sequence Diagram

Component Diagram

Deployment Diagram

Layered Architecture Diagram

Client–Server Diagram

Cloud Architecture Diagram (AWS)

User Flow Diagram

4. How It Works
Infrastructure Components
VPC and Networking
The foundation is a VPC with CIDR block 10.0.0.0/16. This gives 65,536 IP addresses.
Six subnets divide the address space:
- Public: 10.0.1.0/24 and 10.0.2.0/24 (512 IPs total)
- Private: 10.0.11.0/24 and 10.0.12.0/24 (512 IPs total)
- Database: 10.0.21.0/24 and 10.0.22.0/24 (512 IPs total)
A /24 subnet provides 256 IPs minus 5 reserved by AWS. That's 251 usable IPs per subnet.
An Internet Gateway attaches to the VPC. Public subnet route tables point 0.0.0.0/0 traffic to the IGW.
NAT gateways sit in each public subnet. Private subnet route tables point internet traffic to the NAT gateways. This lets private resources download packages and talk to AWS APIs without exposing inbound ports.
Neptune Cluster
The Neptune cluster has one writer instance and two read replicas.
Writer handles all mutations. Read replicas serve queries and provide failover capability.
Instance types start at db.r5.large (2 vCPU, 16 GB RAM). You scale up based on query patterns and dataset size.
Backups happen daily with a 7-day retention window. Point-in-time restore works for up to 35 days.
Encryption at rest uses AWS KMS with a customer-managed key. Encryption in transit enforces TLS 1.2+.
Security Groups
Four security group rules control traffic:
- ALB security group: Allows inbound 443 from 0.0.0.0/0
- Application security group: Allows inbound from ALB security group only
- Neptune security group: Allows inbound port 8182 (Gremlin) from application security group only
- All groups: Allow all outbound traffic
No SSH access. No RDP. If you need to troubleshoot, use Systems Manager Session Manager.
Monitoring and Alerting
CloudWatch tracks these metrics:
- Neptune: CPU utilization, Gremlin request rate, query errors
- Application: Lambda invocations, API Gateway latency, error count
- Infrastructure: Network throughput, disk I/O, memory pressure
Alarms trigger on:
- Neptune CPU > 80% for 5 minutes
- API error rate > 1%
- Lambda throttles > 10 in 1 minute
- Disk space > 85%
SNS topics receive alarm notifications. Email subscribers get alerts immediately.
X-Ray captures distributed traces. You can see exactly where requests slow down.
Request Flow
A typical query follows this path:
- Client sends HTTPS request to API Gateway endpoint
- API Gateway validates JWT token using Lambda authorizer
- Lambda function receives the request event
- Lambda checks ElastiCache for cached graph query result
- On cache miss, Lambda opens connection to Neptune
- Neptune executes Gremlin traversal across graph
- Results stream back to Lambda
- Lambda writes result to ElastiCache with 5-minute TTL
- Lambda returns response to API Gateway
- API Gateway sends response to client
The entire flow typically completes in 50-200ms for cached queries, 200-500ms for uncached queries with good indexing.
Graph Schema Design
Neptune supports property graphs. Each vertex (node) has:
- A unique ID
- A label (type)
- Properties (key-value pairs)
Each edge (relationship) has:
- A unique ID
- A label (relationship type)
- Direction (from vertex A to vertex B)
- Properties
Example schema for fraud detection:
Vertices:
- Account (properties: account_id, created_at, status)
- Device (properties: device_fingerprint, os, browser)
- IPAddress (properties: ip, country, isp)
- Transaction (properties: amount, timestamp, merchant)
Edges:
- Account -[USES]-> Device
- Account -[ACCESSED_FROM]-> IPAddress
- Account -[INITIATED]-> Transaction
- Transaction -[FROM_DEVICE]-> Device
A fraud detection query looks like this in Gremlin:
g.V().has('Account', 'account_id', 'A123')
.out('USES')
.in('USES')
.where(neq('A123'))
.dedup()
.values('account_id')
This finds all accounts that share a device with account A123. In SQL, this would be a complex self-join with device tracking tables.
Communication Patterns
Neptune doesn't have a public endpoint. All access goes through private subnets.
Lambda functions run in the VPC with access to Neptune's security group. This adds cold start latency (1-2 seconds) due to ENI creation. If you need lower latency, use dedicated compute in ECS or EC2.
For streaming data ingestion, use Kinesis Data Streams -> Lambda -> Neptune. Lambda can batch writes for better throughput.
For bulk loading, use the Neptune Bulk Loader. Upload CSV files to S3, then call the loader API. It can load millions of edges per minute.
Important Decisions
Why no public Neptune endpoint? Security. Graph databases often contain sensitive relationship data. Exposing that to the internet is a bad idea.
Why ElastiCache? Graph queries can be expensive. Caching reduces Neptune load by 80-90% in read-heavy workloads.
Why Lambda in VPC despite cold starts? Simplicity and cost. If you're doing < 1000 requests/second, cold starts are fine. Beyond that, switch to ECS Fargate with reserved concurrency.
Why multi-AZ read replicas? Read scaling and failover. Most graph workloads are read-heavy. Splitting reads across replicas improves throughput. If the writer fails, Neptune promotes a replica in 30-60 seconds.
5. Build It Yourself
Prerequisites
You need:
- AWS Account with admin access or IAM permissions for VPC, Neptune, Lambda, CloudWatch
- AWS CLI version 2.13.0 or higher
- Python version 3.9 or higher
- Pulumi version 3.90.0 or higher
Install the AWS CLI:
# macOS
brew install awscli
# Linux
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
# Verify
aws --version
Configure AWS credentials:
aws configure
# Enter:
# AWS Access Key ID: <your-key>
# AWS Secret Access Key: <your-secret>
# Default region: us-east-1
# Default output format: json
Install Pulumi:
# macOS
brew install pulumi/tap/pulumi
# Linux/Windows
curl -fsSL https://get.pulumi.com | sh
# Verify
pulumi version
Environment Setup
Clone the repository:
git clone https://github.com/rahulladumor/graph-database-knowledge-graph.git
cd graph-database-knowledge-graph
Create a Python virtual environment:
python3 -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
Install dependencies:
pip install -r requirements.txt
Configuration
Initialize Pulumi stacks:
# Create development stack
pulumi stack init dev
# Create production stack
pulumi stack init prod
Set configuration values:
# Development stack
pulumi config set aws:region us-east-1
pulumi config set environment dev
pulumi config set neptune:instanceClass db.r5.large
pulumi config set neptune:replicaCount 1
# Production stack
pulumi stack select prod
pulumi config set aws:region us-east-1
pulumi config set environment prod
pulumi config set neptune:instanceClass db.r5.xlarge
pulumi config set neptune:replicaCount 2
pulumi config set enableBackups true
pulumi config set enableMonitoring true
Deployment Steps
Deploy to development:
pulumi stack select dev
pulumi up
# Review the preview
# Type "yes" to confirm
Pulumi will create:
- VPC with 6 subnets
- Internet Gateway and NAT Gateways
- Security groups
- Neptune cluster with replicas
- CloudWatch dashboards
- SNS topics for alerts
Deployment takes 10-15 minutes. Neptune cluster creation is the slowest part.
After deployment, Pulumi outputs:
Outputs:
bucket_name: "dev-bucket-a1b2c3d4"
neptune_endpoint: "dev-neptune-cluster.cluster-xyz123.us-east-1.neptune.amazonaws.com"
neptune_port: 8182
vpc_id: "vpc-abc123def456"
Common Mistakes
Issue: Error: creating EC2 VPC: VpcLimitExceeded
Fix: You've hit the VPC limit (5 per region by default). Delete unused VPCs or request a limit increase.
Issue: Error: No default VPC found
Fix: The code assumes a default VPC exists. Either create one or modify the Pulumi code to specify VPC CIDR blocks explicitly.
Issue: Neptune cluster creation fails with "Insufficient subnet coverage"
Fix: Neptune requires at least two subnets in different AZs. Check your subnet configuration.
Issue: Lambda can't connect to Neptune
Fix: Ensure Lambda is in the VPC and its security group allows outbound to Neptune's security group on port 8182.
Issue: High NAT Gateway costs
Fix: If you're transferring lots of data, consider VPC endpoints for S3 and DynamoDB. They're free and bypass NAT gateways.
Verification
Test the Neptune cluster:
# SSH into a bastion host in the VPC (you'll need to add one)
ssh ec2-user@<bastion-ip>
# Install Gremlin console
wget https://archive.apache.org/dist/tinkerpop/3.5.1/apache-tinkerpop-gremlin-console-3.5.1-bin.zip
unzip apache-tinkerpop-gremlin-console-3.5.1-bin.zip
cd apache-tinkerpop-gremlin-console-3.5.1
# Connect to Neptune
bin/gremlin.sh
:remote connect tinkerpop.server conf/neptune-remote.yaml
:remote console
# Run a test query
g.V().count()
If you see ==>0, Neptune is working. The graph is empty because you haven't loaded data yet.
6. Key Code Sections
Main Pulumi Program
The entry point is __main__.py:
"""Main Pulumi program"""
import pulumi
import pulumi_aws as aws
# Configuration
config = pulumi.Config()
environment = config.get("environment") or "dev"
# Example S3 bucket
bucket = aws.s3.Bucket(f"{environment}-bucket",
tags={
"Environment": environment,
"ManagedBy": "Pulumi"
})
# Exports
pulumi.export("bucket_name", bucket.id)
This is a minimal starter. In production, you'd add:
- VPC and networking resources
- Neptune cluster and subnet groups
- IAM roles and policies
- Lambda functions
- CloudWatch dashboards
Project Configuration
The Pulumi.yaml file defines the project:
name: graph-database-knowledge-graph
runtime: python
description: Graph Database Knowledge Graph
The runtime: python setting tells Pulumi to use the Python runtime. You can use TypeScript, Go, or C# instead.
Dependencies
The requirements.txt specifies Python packages:
pulumi>=3.0.0
pulumi-aws>=6.0.0
Pulumi versions matter. Breaking changes happen between major versions. Always pin to a specific version range.
Why This Structure Matters
Pulumi code is declarative. You describe the desired state. Pulumi figures out what to create, update, or delete.
The environment variable lets you create multiple isolated stacks from the same code. Dev stack uses small instances. Prod stack uses larger instances with more replicas.
Exporting outputs like bucket_name makes them available to other Pulumi stacks or external tools. You can reference outputs in CI/CD pipelines or application config.
7. Running in Production
Logging
All logs go to CloudWatch Logs.
Neptune query logs are disabled by default (they're expensive). Enable them for debugging:
aws neptune modify-db-cluster \
--db-cluster-identifier dev-neptune-cluster \
--cloudwatch-logs-export-configuration '{"EnableLogTypes":["audit"]}'
Lambda logs automatically stream to CloudWatch. Set retention to 7 days for dev, 30 days for prod.
VPC Flow Logs capture all network traffic. Enable them for security auditing:
aws ec2 create-flow-logs \
--resource-type VPC \
--resource-ids vpc-abc123 \
--traffic-type ALL \
--log-destination-type cloud-watch-logs \
--log-group-name /aws/vpc/flowlogs
Monitoring
Key metrics to watch:
Neptune:
CPUUtilization: Should stay below 70%VolumeBytesUsed: Track growth rateGremlinRequestsPerSec: Query throughputGremlinErrors: Should be near zero
Lambda:
Invocations: Total request countErrors: Failed invocationsDuration: Query latencyThrottles: Rate limiting events
API Gateway:
Count: Request volume4XXError: Client errors5XXError: Server errorsLatency: End-to-end response time
Create CloudWatch dashboards for each environment. Set up alerts for abnormal patterns.
Deployment Verification
After deploying, run these checks:
Monitoring test: Trigger a CloudWatch alarm
aws cloudwatch set-alarm-state \
--alarm-name neptune-cpu-high \
--state-value ALARM \
--state-reason "Testing alert"
Security test: Verify no public access
nmap -p 8182 <neptune-endpoint>
# Should timeout or be filtered
Connectivity test: Query Neptune from Lambda
from gremlin_python.driver import client
neptune_client = client.Client('wss://neptune-endpoint:8182/gremlin', 'g')
result = neptune_client.submit('g.V().count()').all().result()
print(result) # Should print [0] for empty graph
Health check: Verify Neptune cluster status
aws neptune describe-db-clusters --db-cluster-identifier prod-neptune-cluster
# Status should be "available"
Debugging
Problem: Queries are slow
Debug: Enable Neptune query logging. Check for missing indexes. Add vertex/edge indexes using Gremlin:
g.V().has('Account', 'account_id', 'A123') // Without index: 2000ms
// Add index, then retry: 50ms
Problem: Connection timeouts
Debug: Check security groups. Verify Lambda is in correct VPC subnets. Test with longer Lambda timeout (30s instead of 3s).
Problem: High costs
Debug: Check CloudWatch Metrics usage (detailed monitoring costs add up). Review Neptune instance types. Consider downgrading dev environments.
Common Runtime Issues
Issue: Neptune cluster in "backing-up" state
Impact: Writes may be slower
Solution: Wait for backup to complete (5-15 minutes). Schedule backups during low-traffic windows.
Issue: Read replica lag
Impact: Stale data in queries
Solution: Query the writer endpoint for consistent reads. Increase replica instance size if lag persists.
Issue: Lambda cold starts > 5 seconds
Impact: Poor user experience
Solution: Enable provisioned concurrency. Or move to ECS Fargate for persistent connections.
Health Confirmation
A healthy system shows:
- ✅ All Neptune instances in "available" state
- ✅ CPU utilization between 20-60%
- ✅ No CloudWatch alarms in ALARM state
- ✅ API Gateway 5XX error rate < 0.1%
- ✅ Lambda concurrent executions below account limit
- ✅ VPC flow logs showing expected traffic patterns
8. Cost Analysis
Real Cloud Cost Expectations
Development Environment (~$300/month):
| Component | Specification | Monthly Cost |
|---|---|---|
| Neptune | 1x db.r5.large writer | ~$220 |
| Neptune | 1x db.r5.large reader | ~$220 |
| NAT Gateway | 2x NAT gateways | ~$65 |
| Data Transfer | 100 GB outbound | ~$9 |
| CloudWatch | Logs + metrics | ~$15 |
| S3 | 50 GB storage | ~$1 |
| Subtotal | ~$530 |
With auto-shutdown (12 hours/day): ~$300/month
Production Environment (~$1,200-2,500/month):
| Component | Specification | Monthly Cost |
|---|---|---|
| Neptune | 1x db.r5.xlarge writer | ~$440 |
| Neptune | 2x db.r5.xlarge readers | ~$880 |
| NAT Gateway | 2x NAT gateways | ~$65 |
| Data Transfer | 500 GB outbound | ~$45 |
| CloudWatch | Detailed monitoring | ~$75 |
| ElastiCache | 1x cache.r6g.large | ~$110 |
| Lambda | 10M invocations | ~$20 |
| S3 | 500 GB + requests | ~$15 |
| Subtotal | ~$1,650 |
Can reach $2,500+ with high data transfer or more Neptune replicas
Most Expensive Components
- Neptune instances (70-80% of total cost)
- db.r5.xlarge costs $0.60/hour = $440/month
- Scales linearly with instance size and replica count
- NAT Gateways (~$65/month flat)
- $0.045/hour per gateway
- $0.045/GB processed
- Often forgotten cost driver
- Data Transfer (variable)
- Free within same AZ
- $0.01/GB between AZs
- $0.09/GB to internet
- Can spike unexpectedly
- CloudWatch ($15-75/month)
- Detailed monitoring: $0.30 per instance per month
- Logs ingestion: $0.50/GB
- Logs storage: $0.03/GB/month
Optimization Options
Option 1: Auto-shutdown dev environments
Savings: ~40%
How: Stop Neptune instances after hours
aws neptune stop-db-cluster --db-cluster-identifier dev-neptune
Option 2: Use smaller instances for dev
Savings: ~50% on dev
Trade-off: Slower queries, less representative testing
Option 3: Single-AZ for dev
Savings: ~50% on Neptune
Trade-off: No high availability, longer failover
Option 4: VPC endpoints for S3/DynamoDB
Savings: ~$30-40/month
How: Free data transfer, avoid NAT gateway costs
Option 5: Reserved instances (1-year)
Savings: ~35%
Trade-off: Upfront payment, locked into instance type
Option 6: ElastiCache only in prod
Savings: ~$110/month
Trade-off: Dev queries hit Neptune directly
Architectural Tradeoffs
Multi-AZ vs Single-AZ:
- Multi-AZ: 2x cost, 99.99% uptime, automatic failover
- Single-AZ: Half the cost, 99.9% uptime, manual recovery
Neptune vs Self-Managed Neo4j:
- Neptune: Higher monthly cost, zero ops overhead
- Neo4j on EC2: Lower compute cost, high ops cost (backups, patching, scaling)
Serverless (Lambda) vs Dedicated (ECS):
- Lambda: Pay per request, cold starts, $0.20 per 1M requests
- ECS Fargate: Fixed cost (~$30/month for small task), no cold starts
ElastiCache vs No Cache:
- With cache: +$110/month, 80% fewer Neptune queries, 5x faster responses
- Without cache: $0 extra, higher Neptune load, slower queries
For most production workloads, the cache pays for itself in improved user experience and reduced Neptune load.
9. Final Thoughts
Limitations
This infrastructure framework is a starting point, not a complete solution.
Missing pieces:
- No actual Neptune cluster definition (just an S3 bucket placeholder)
- No Lambda functions for queries
- No graph schema or data model
- No authentication/authorization
- No CI/CD pipeline
- No bulk data loading scripts
You need to build these on top of the foundation.
Neptune limitations:
- No native Cypher support (Neo4j's query language)
- openCypher support is available but less mature than Gremlin
- Query performance degrades with very large graphs (>100M edges)
- Limited control over query execution plans
- Backup/restore is slower than RDS (graph data is complex)
Cost considerations:
- Neptune is expensive for small datasets
- For <1M edges, consider DynamoDB with graph queries
- For >100M edges, consider sharding or graph partitioning
Lessons Learned
1. VPC configuration is critical
Getting subnets, route tables, and security groups right takes time. Use a VPC module rather than building from scratch.
2. Neptune has a learning curve
Gremlin syntax is different from SQL. Graph thinking requires practice. Budget time for learning.
3. Monitoring is non-negotiable
Without CloudWatch dashboards, you're flying blind. Set up monitoring on day one, not after something breaks.
4. Testing graph queries is hard
Unit testing Gremlin traversals requires mocking or test clusters. CI/CD for graph databases is an unsolved problem.
5. Cost optimization requires constant attention
Leaving dev clusters running costs $300+/month. Auto-shutdown saves thousands annually.
When NOT to Use This Approach
Scenario 1: Simple key-value lookups
Use DynamoDB instead. It's faster and cheaper for non-graph queries.
Scenario 2: Small datasets (<10K vertices)
Use a relational database. The overhead of Neptune isn't worth it.
Scenario 3: Batch analytics on graphs**
Use EMR with Spark GraphX or custom Gremlin jobs. Neptune is optimized for OLTP, not analytics.
Scenario 4: Tight budget constraints**
Neptune starts at ~$400/month. If you're cost-sensitive, run Neo4j Community Edition on EC2 for ~$50/month.
Scenario 5: Need for self-hosted compliance**
Some regulations require on-premise deployments. Neptune is AWS-only.
Future Improvements
Short term (next sprint):
- Complete Neptune cluster implementation in Pulumi
- Add Lambda functions with Gremlin queries
- Implement basic graph schema (accounts, devices, transactions)
- Add CloudWatch dashboards
Medium term (next quarter):
- Build CI/CD pipeline with automated testing
- Add bulk data loading from S3
- Implement caching layer with ElastiCache
- Create sample fraud detection queries
Long term (next 6 months):
- Graph partitioning for >100M edges
- Real-time streaming ingestion with Kinesis
- GraphQL API layer over Gremlin
- Machine learning on graph data (link prediction, community detection)
- Multi-region replication for disaster recovery
Conclusion
Building production-grade graph database infrastructure is complex.
You need to handle networking, security, monitoring, cost optimization, and disaster recovery. Infrastructure as Code makes this repeatable and testable.
This project provides a blueprint for Neptune deployments using Pulumi. The foundation is solid: multi-AZ VPC, isolated subnets, security groups, monitoring.
What's missing is the application layer. Graph schemas, query patterns, data ingestion, caching, APIs. Those are domain-specific. You build them on top.
If you're doing relationship-heavy workloads—fraud detection, recommendation systems, knowledge graphs, network analysis—Neptune is worth considering. The managed service eliminates ops overhead.
Just be aware of costs. Start small. Optimize as you learn your query patterns.
The code is on GitHub. The license is MIT. Use it, extend it, contribute back.
Resources
- Repository: github.com/rahulladumor/graph-database-knowledge-graph
- AWS Neptune Documentation: docs.aws.amazon.com/neptune
- Pulumi AWS Provider: pulumi.com/registry/packages/aws
- Gremlin Language: tinkerpop.apache.org/docs/current/reference
- Author's Blog: acloudwithrahul.in
Copyright © 2024 Rahul Ladumor
License: MIT License
Version: 1.0.0
Made with ❤️ for the cloud infrastructure community