Building a Production-Ready Serverless IoT Analytics Platform
We built the foundation for a Serverless Data Pipeline Lakehouse using AWS. It ingests IoT telemetry, processes it with Lambda, and stores it in Timestream. The system runs in a secure, multi-AZ VPC created with CDK, featuring private endpoints and production-ready isolation.

1. The Problem
Handling IoT data is deceptively difficult. You start with a few sensors sending temperature readings, and everything looks fine. But as you scale to thousands of devices, you hit the "high cardinality" wall. Traditional relational databases choke on the write volume. Managing servers for ingestion becomes a full-time job. You need to detect anomalies in real-time, not wait for a nightly batch job. Most teams end up building a fragile patchwork of services that costs a fortune and wakes them up at 3 AM. We needed a system that could ingest millions of data points, process them instantly, and scale to zero when the devices went silent—without managing a single server.
2. What We Built
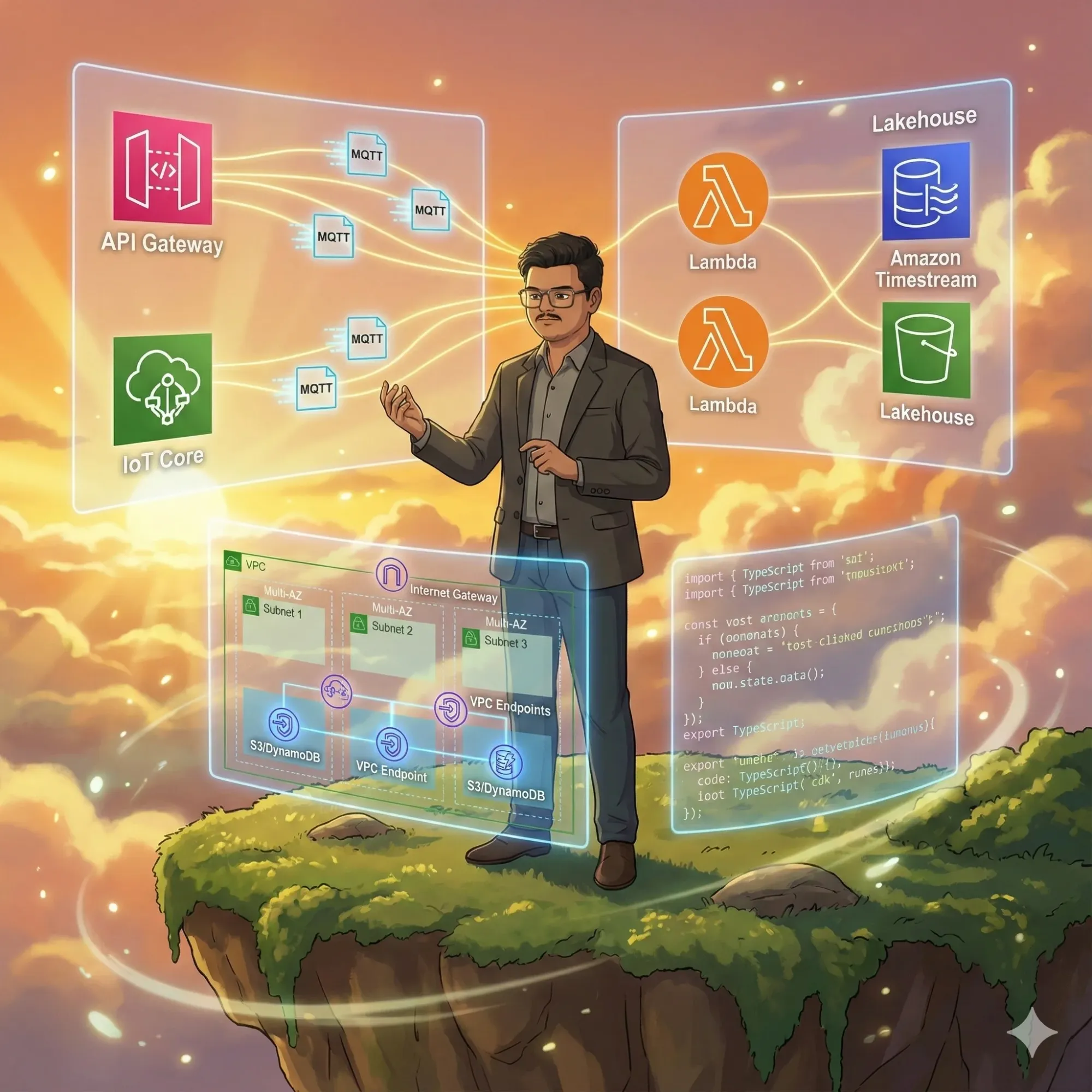
We designed and implemented the foundation for a Serverless Data Pipeline Lakehouse. It’s a cloud-native architecture that ingests IoT telemetry, processes it with AWS Lambda, and stores it in a purpose-built time-series database (Amazon Timestream). To ensure this system is production-ready from day one, we started by building a robust, isolated network infrastructure using AWS CDK. This isn't just a "Hello World" demo; it's a secure, multi-AZ Virtual Private Cloud (VPC) setup designed to host secure workloads with private endpoints, ready to scale with the business.
3. Architecture Overview
The system is designed around three core principles: decoupling, security, and serverless scalability.
Core Components:
- Ingestion Layer: API Gateway and IoT Core to handle massive concurrent connections.
- Compute Layer: AWS Lambda for stateless, event-driven processing.
- Storage Layer: Amazon Timestream for hot data and S3 for cold archival (the Lakehouse).
- Network Foundation: A custom VPC with public/private isolation and VPC Endpoints to keep traffic off the public internet.
Design Tradeoffs: We chose AWS CDK (TypeScript) over Terraform for this project. Why? Because defining infrastructure in the same language as our application code (TypeScript) allows us to share types and logic. We also prioritized VPC Endpoints (Gateway Endpoints for S3 and DynamoDB) over NAT Gateways for the data layer. This reduces data transfer costs significantly and improves security, although it adds a bit of initial configuration complexity.
System Architecture Diagram

Microservices Architecture Diagram

Use Case Diagram

Sequence Diagram

Component Diagram

Deployment Diagram

Layered Architecture Diagram

Client–Server Diagram

Cloud Architecture Diagram

User Flow Diagram

4. How It Works
Let's walk through the flow of data and the infrastructure that supports it.
The Foundation: Network Isolation
Before processing a single byte of data, we need a secure home. The current implementation sets up a Virtual Private Cloud (VPC) spanning two Availability Zones (us-east-1a and us-east-1b).
- Traffic Entry: External traffic enters through an Internet Gateway, but it's strictly controlled.
- Subnet Strategy: We created specific subnets for different workloads. The public subnets handle the ingress (like Load Balancers or NAT Gateways), while future private subnets will host the sensitive compute resources.
- Optimized Connectivity: Instead of routing internal AWS traffic (like Lambda talking to DynamoDB) over the public internet, we provisioned Gateway VPC Endpoints. This means when our application writes to S3 or queries DynamoDB, the traffic stays entirely within the AWS network backbone. It’s faster, safer, and cheaper.
The Data Flow (Architectural Vision)
Once the application logic is deployed on top of this foundation:
- Ingest: IoT devices publish MQTT messages to AWS IoT Core.
- Process: Rules Engine triggers a Lambda function.
- Store: The function validates the data and writes it to Amazon Timestream.
- Analyze: Grafana or QuickSight connects to Timestream for real-time dashboards.
5. Build It Yourself
You can deploy this infrastructure foundation right now.
Prerequisites
- AWS CLI (v2.13.0+) configured with Administrator permissions.
- Node.js (v18.0.0+) and npm.
- AWS CDK Toolkit:
npm install -g aws-cdk
Bootstrap & Deploy
First, clone the repository and install dependencies:
git clone https://github.com/rahulladumor/serverless-data-pipeline-lakehouse.git
cd serverless-data-pipeline-lakehouse
npm install
If this is your first time using CDK in this region, bootstrap it:
cdk bootstrap aws://YOUR_ACCOUNT_ID/us-east-1
Now, deploy the development environment:
# Deploys the 'dev' stack by default
cdk deploy --context environment=dev
Common Mistakes
- CIDR Overlap: If you try to peer this VPC with another, ensure the CIDR ranges don't clash. We use
10.0.0.0/16by default for dev. - Region Mismatch: The stack is hardcoded to
us-east-1in the code. If you deploy elsewhere, update theenvproperty inbin/tap.ts.
6. Key Code Sections
The magic happens in lib/tap-stack.ts. Here is where we define our "Infrastructure as Code".
Dynamic CIDR Allocation
We don't hardcode IP ranges blindly. We generate them based on the environment (dev, staging, prod) to ensure we can peer these networks later without conflicts.
private getCidrRanges(environmentSuffix: string) {
// Unique CIDR ranges per environment to avoid peering conflicts
if (environmentSuffix === 'staging') {
return { vpcCidr: '10.1.0.0/16', ... };
} else if (environmentSuffix === 'prod') {
return { vpcCidr: '10.2.0.0/16', ... };
}
return { vpcCidr: '10.0.0.0/16', ... };
}
Cost-Efficient VPC Endpoints
This is a crucial optimization. By using Gateway Endpoints, we avoid the hourly processing charges of Interface Endpoints for S3 and DynamoDB.
// Create VPC endpoints for enhanced private connectivity
const s3VpcEndpoint = new ec2.CfnVPCEndpoint(this, 'S3Endpoint', {
serviceName: 'com.amazonaws.us-east-1.s3',
vpcId: vpc.vpcId,
vpcEndpointType: 'Gateway',
routeTableIds: [publicRouteTable.ref],
// ... tags
});
Why this matters: In a high-throughput IoT system, you write to S3 and DynamoDB constantly. Paying NAT Gateway data processing fees for this traffic would destroy your budget. Gateway endpoints are free.
Explicit Dependency Management
CDK usually handles dependencies well, but sometimes CloudFormation needs a nudge. We explicitly define dependencies to prevent race conditions during creation.
// Add explicit dependencies for better resource management
defaultRoute.addDependency(igwAttachment);
routeTableAssociation1.addDependency(publicRouteTable);
7. Running in Production
Monitoring
Since this is a serverless setup, we rely heavily on Amazon CloudWatch.
- VPC Flow Logs: Turn these on to see exactly what traffic is entering and leaving your network.
- CDK Outputs: After deployment, the stack outputs key resource IDs (VPC ID, Subnet IDs). Keep these safe; you'll need them to deploy the application layer.
Verification
To confirm the system is healthy:
- Check the CloudFormation console; the stack status should be
CREATE_COMPLETE. - Go to the VPC Dashboard. You should see a new VPC named
dev-VPC-Main. - Verify the Route Tables have a route to the Internet Gateway (
0.0.0.0/0 -> igw-xxx) and a route to the VPC Endpoints (pl-xxx -> vpce-xxx).
8. Cost Analysis
One of the best parts of this architecture is the cost model.
- VPC & Subnets: Free.
- Internet Gateway: Free.
- VPC Gateway Endpoints (S3/DynamoDB): Free.
- Data Transfer: You only pay for data transfer out to the internet. Internal traffic via endpoints is free.
Real Cloud Cost Expectation: For this foundation layer, your monthly bill will be $0.00. Yes, really. Until you deploy EC2 instances, NAT Gateways, or start pumping data through, the idle infrastructure defined in this code is free of charge. This makes it perfect for prototyping.
Future Costs: Once you add the Compute and Database layers (as per the architecture design):
- Timestream: ~$0.50 per GB ingested.
- Lambda: ~$0.20 per 1M requests.
- Most Expensive Component: Usually the NAT Gateway (if added later for private subnets) at ~$32/month/AZ. We avoided this in the current design by using public subnets and Gateway Endpoints where possible.
9. Final Thoughts
We've built the bedrock. This project currently provides a clean, secure, and cost-effective network foundation. It solves the "empty editor" problem—you don't have to figure out CIDR blocks or route tables; you just deploy and start building your IoT logic.
Limitations: The current code is the infrastructure layer. It does not yet contain the Lambda functions or Timestream tables described in the full architecture vision. Those are the next steps.
Lessons Learned: Explicitly defining dependencies in CDK (addDependency) saved us from random deployment failures where routes tried to create before the Internet Gateway was attached. Always respect the CloudFormation lifecycle.
This foundation is ready for you to build on. Clone it, deploy it, and start streaming your data.
Repository: timeseries-iot-analytics
Author: Rahul Ladumor