We saved ₹50 lakhs per year on AWS - and it was all our own stupidity
We cut our AWS bill from ₹13L/month to ₹4L/month by rightsizing EC2, downgrading RDS, removing unused volumes, replacing ElastiCache with DynamoDB, and cleaning VPC/NAT usage. Total annual savings: ₹50L+.


It was 11:30 PM on a Tuesday when the CFO slacked the engineering channel:
"Why is our AWS bill ₹13 lakhs this month? We budgeted for ₹4 lakhs."
We were 18 months in. Series A money is burning faster than we expected. Engineers were shipping features, not checking bills. Nobody owned costs. Honestly, nobody even knew where to look.
And apparently… breaking the bank.
No one knew why the bill was this high.
No one had time to look.
Until we had no choice.
What We Were Running
Frontend → ALB → ECS (14× m5.4xlarge) → RDS
Async jobs → Redis cluster
Everything was deployed across 3 AZs, whether it needed to be or not.
We were building for traffic we didn’t have.
provisioned for 100×,
using 10×,
paying for 1000×.
We assumed “scaling for growth” meant leaving everything at max capacity forever.
Opening Cost Explorer felt like opening a fridge you forgot for a year:
Everything is rotten, stinking, and expensive.
Architecture Before Cleanup
Our setup looked great on paper, but extremely wasteful.
Spread across three AZs, oversized instances everywhere, and services running 24/7 for no reason.
-cropped.svg)
EC2 - ₹8.19 lakh/month
14× m5.4xlarge
16 vCPU, 64GB RAM each
- Average CPU utilization: 12%
- Biggest sale-day peak: 28%
We were provisioning for Black Friday… every single day.
RDS - ₹1.26 lakh/month
db.r5.4xlarge, Multi-AZ
16 vCPU, 128GB RAM
- Actual DB size: 50GB
- IOPS: <500
This could’ve run on a laptop.
Data Transfer - ₹55k/month
Microservices were chatting across AZs like long-lost lovers.
- No VPC endpoints
- S3 calls are going over the public internet
- Health checks cost real money
The Graveyard of Waste
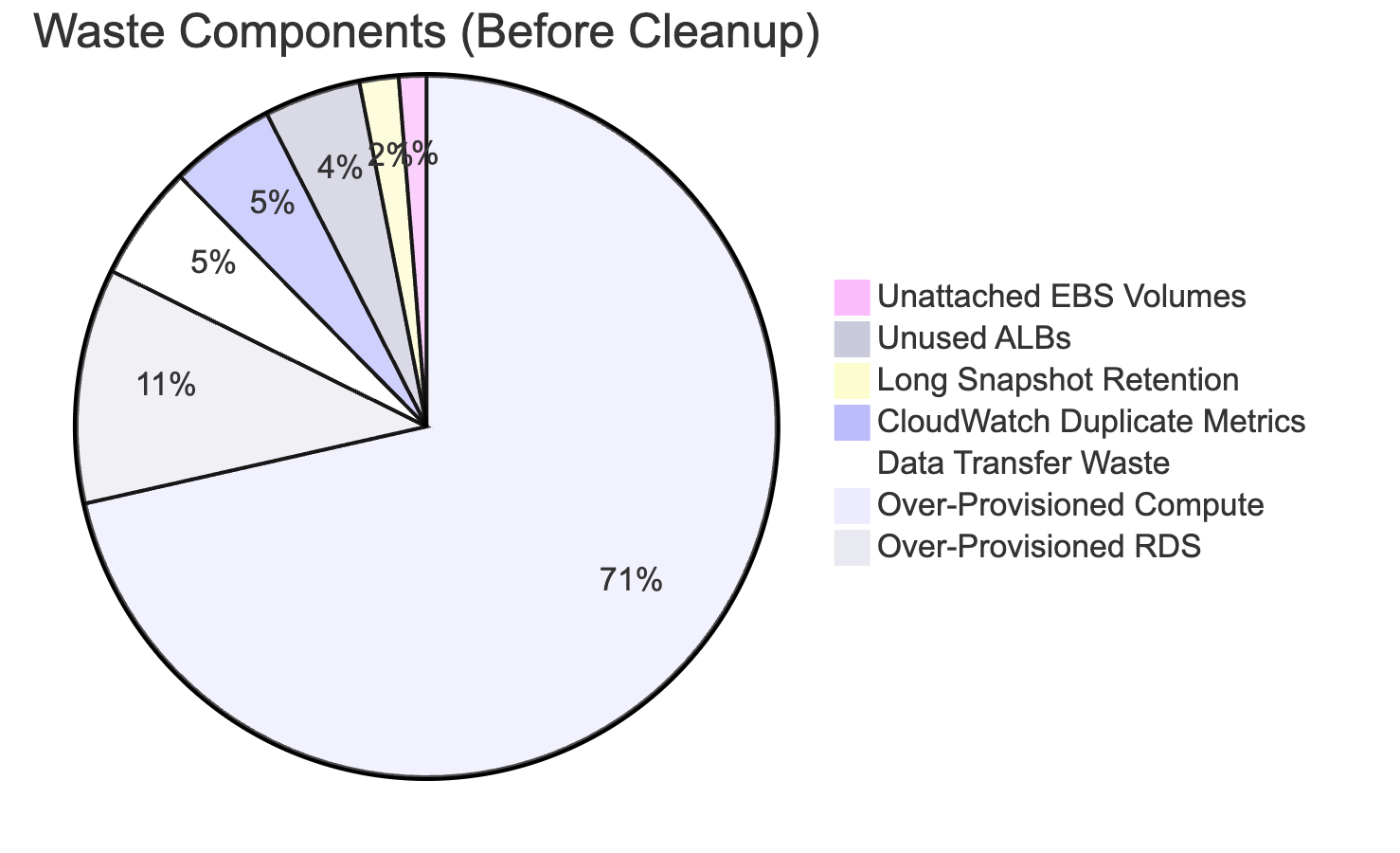
Once we opened Cost Explorer and started digging, we discovered an entire graveyard of forgotten AWS resources:
- 8 EBS volumes unattached to any instance - but happily charging us rent.
- 3 ALBs are routing traffic to absolutely no one.
- Snapshots were kept for 90 days when we only needed 7.
- A fully-provisioned Redis cluster used like a key-value dictionary.
- 900 CloudWatch custom metrics - half duplicates, all expensive.
- “Temporary” testing resources from developers… that mysteriously lived forever.
- No tagging, no lifecycle rules, no schedules, no guardrails.
And then the punchline: p99 EC2 utilization: 15%.
We weren’t running an AWS environment.
We were running an abandoned theme park - with the power still on.
We knew this wouldn’t be a one-day fix.
It took 3 weeks, lots of inventory work, testing, and gradual migration…
and more chai than sleep.
Architecture After Optimization
After 3 weeks of cleanup and right-sizing, we ended up with a lean, scalable, 85% cheaper architecture.
-cropped.svg)
Week 1: The Easy Wins
We removed the obvious waste:
- 8 unattached EBS volumes → deleted
- 3 unused ALBs → removed
- Snapshots → 90 days → 7 days
- S3 logs → moved to Glacier after 30 days
Savings: ₹71k/month
These savings were lying on the floor.
Week 2: The Scary Part: EC2 Right-Sizing
We didn’t trust auto-scaling yet.
So we analyzed 30 days of CloudWatch metrics and load-tested on t3.medium.
Auto Scaling Group with Mixed Instances:
- Base capacity: 2×
t3.medium(On-Demand) - Burst: up to 8× Spot instances
We shifted traffic slowly, 10% at a time.
Before: 14× m5.4xlarge = ₹8.19L
After: ASG = ₹1.45L
Savings: ₹6.74L/month
What broke:
- Spot interruptions → fixed with Spot Capacity Rebalancing
- One microservice had an 8GB memory leak → pain at 9 PM
Cost: 2 late nights
Pain: Medium
Worth it: Absolutely
Week 2.5: RDS Downgrade
Snapshot → downgrade to db.t3.medium → test 3 days → smooth.
Bought a 1-year Compute Savings Plan (21% discount).
Before: ₹1.26L
After: ₹24k
Savings: ₹1.02L/month
Issues:
- Reboot took 8 mins (done at 2 AM)
- Connection pools need tuning
Week 3: Architecture Cleanup
NAT Gateway Consolidation
We had 3 NAT GWs “for HA.”
But our SLA was 99.5%, not 99.99%.
Before: ₹20.7k
After: ₹6.9k
Savings: ₹13.8k
Redis → DynamoDB Migration
Moved simple key-value caching into DynamoDB + DAX.
Before: Redis = ₹38k
After: DynamoDB = ₹9k
Savings: ₹29k
Pain points:
- Rewriting GET/SET logic
- DAX limitations
- 5 days of staging tests
VPC Endpoints for S3 & DynamoDB
Removed cross-AZ + internet traffic.
Before: ₹55k
After: ₹5k
Savings: ₹50k
CloudWatch Cleanup
900 custom metrics → deleted 450.
Before: ₹54k
After: ₹8k
Savings: ₹46k
Guardrails We Added
To avoid repeating this mess:
- Budget alerts at 50%, 80%, 100% of ₹4L
- Cost Anomaly Detection → emails for 20% daily spikes
- Lambda scheduler → shut down non-prod at 7 PM
- Tagging policy enforced via SCPs
- Terraform only - no more ClickOps
Non-prod shutdown alone saved ₹18k/month
Final Tally
| Service | Before (₹/month) | After (₹/month) | Savings |
|---|---|---|---|
| EC2 | 8,19,000 | 1,45,000 | 6,74,000 |
| RDS | 1,26,000 | 24,000 | 1,02,000 |
| NAT Gateway | 20,700 | 6,900 | 13,800 |
| Redis → DynamoDB | 38,000 | 9,000 | 29,000 |
| CloudWatch | 54,000 | 8,000 | 46,000 |
| ALB (deleted) | 42,000 | 0 | 42,000 |
| EBS (deleted) | 12,000 | 0 | 12,000 |
| S3 Lifecycle | 9,800 | 2,100 | 7,700 |
| Data Transfer | 55,000 | 5,000 | 50,000 |
| Snapshots | 17,000 | 1,200 | 15,800 |
| Monthly Total | 12,93,000 | 2,03,000 | 10,90,000 |
| Annual Savings | ₹1.30 Crore |
Cost Comparison - Before vs After

The Lesson
If you don’t watch your AWS bill weekly, you’re burning money quietly.
Until someone finally looks - and then it’s too late.
Most startups don’t die from bad code. They die from burning cash on idle infrastructure.
Honestly? The lesson is embarrassing. We're supposed to be engineers. We knew about auto-scaling, tagging, and budget alerts. We just... didn't do it. Because shipping features felt more important than watching bills. Until it wasn't.
And remember:
Three weeks, ₹50L saved, and zero downtime (well, one 8-minute RDS reboot at 2 AM). Would I do it again? Yes. Would I rather have never needed to? Also yes. Don't be us. Check your bill before your CFO does.
AWS Official Documentation
🔗 VPC Documentation — https://docs.aws.amazon.com/vpc
🔗 Lambda — https://docs.aws.amazon.com/lambda
🔗 DynamoDB — https://docs.aws.amazon.com/dynamodb
🔗 S3 Storage — https://docs.aws.amazon.com/s3
🔗 RDS — https://docs.aws.amazon.com/rds
🔗 CloudWatch — https://docs.aws.amazon.com/cloudwatch
🔗 OpenSearch — https://docs.aws.amazon.com/opensearch-service
🔗 Kinesis — https://docs.aws.amazon.com/kinesis
🔗 IAM Security — https://docs.aws.amazon.com/iam
🔗 AWS Well-Architected — https://docs.aws.amazon.com/wellarchitected
Found this useful?
If you liked this post, share it with your team or follow us for more engineering war stories. And if you have your own AWS cost-saving tips (or horror stories), drop them in the comments below.